Hi, dear readers! Welcome to my blog. On this post, last on our series, we will finally talk about the most known new feature of Java 9, Jigsaw. But after all, why do we need a module system? Let’s find out!
In the beginning
At Java’s beginnings, we have several types of ways to encapsulate applications. There is the most generic unit, know as JAR, and there’s also other more specific formats, such as WARs for web applications and EARs for Enterprise Java Beans (EJB) applications.
This applications, typically speaking, do not consist of only code that was written by the developers teams themselves: there is also a plethora of libraries and frameworks that are also imported, such as logging libraries, ORM frameworks, web frameworks, etc.
Generally speaking, each of this libraries and frameworks are packaged as JARs as well, and their dependencies are also packaged as JARs. This results on a scenario that we have a really big amount of dependencies included on a single application, just to make the whole thing work. The picture bellow shows a typical Spring Boot application’s classpath. It is possible to note the overwhelming mountain of dependencies:
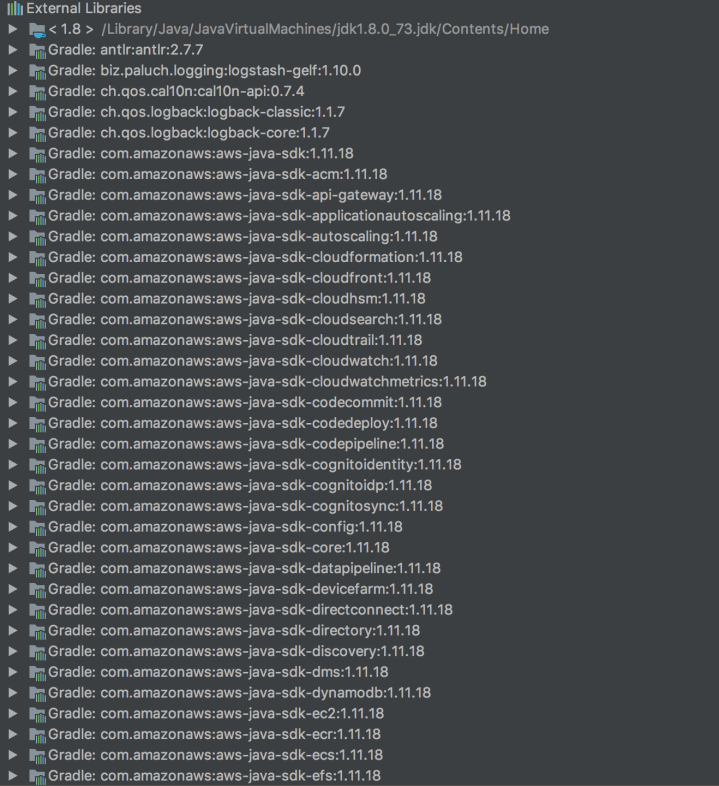
Fragment of a typical Spring Boot Application dependencies list. It is 267 items long!
Jar hell
The situation stated previously leads us to the infamous Jar hell. This term refers to all problems the developers suffer across more then 20 years of Java, such as ClassNotFoundExceptions, when the application can’t found a certain class, or NoClassDefFoundError, when there’s multiple versions of the same class and the application can’t decide which version to use.
Encapsulation problems
Another problem we got is encapsulation. Once a dependency is formed, all the classes from the imported package are accessible to the importer. Even if we declare a class with the default visibility access, it is still possible to access the class, just by using the same package name of the class we want to use – don’t try this at home, folks!.
This leads to poor possibilities on interface designs, since we can’t really avoid certain classes to not been exposed to the outside world.
Performance degradation
Another big problem is performance. This is specially felt on Java EE containers, since servers need to support a big list of features provided for applications. It is true that we had efforts on the past to improve this situation, such as EAP profiles on JBoss server, but still, the situation was far from resolved.
This results on heavy, clunky servers, that can be slow to operate and specially to initialize, alongside intensely memory demanding.
Enter the modules
To solve all the problems we saw on the previous sections, on Java 9 we got Jigsaw, the new module system for Java.
With jigsaw, we can create modules from packages inside a application, allowing a much more coherent and organized structure. Not only that, with modules, we have to explicit declare what we want to expose from a module, so we also eliminate the encapsulation problems we talked about earlier.
This also helps with the performance degradation we just saw, since with modules the amount of classes and packages to be loaded from the servers can be significantly reduced, resulting and thinner servers.
So,let’s see how modules work on practice!
Creating a module
Let’s start by creating a simple project. the source code for this lab is on this link, the project was created using Intellij IDEA.
To create a project, all we have to do is create a java file called module-info.java and place it at the root of the package structure we want to encapsulate on a module. The result is something like the image bellow:
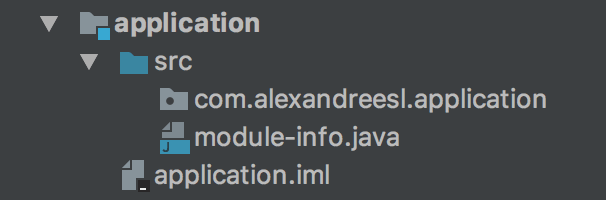
Inside the file, we define a module, that it is something like this:
module com.alexandreesl.application {
}
Now, the keyword module is reserved on Java. On the code above we defined a module which name must match the package’s name. That’s it! Our first module! Now, let’s see how to make this module to talk with other modules
Separating a application in different modules
Our sample application will consist of 4 modules: a main module, a dao module, a service module and a model module.
To create the different modules, all we have to do is create the different packages and module definitions – the module-info.java files – , creating the whole module structure.
The image bellow shows the structure:
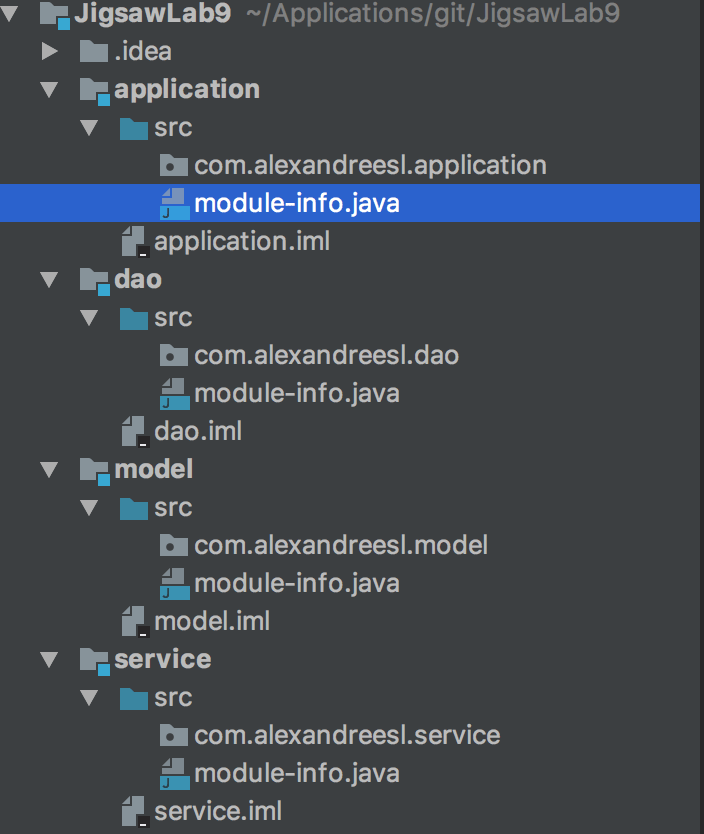
And the new module definitions are:
module com.alexandreesl.dao {
}
module com.alexandreesl.model {
}
module com.alexandreesl.service {
}
Exposing a module
Now that we have the modules defined, let’s start coding our project. Our project will represent a simple CRUD of books, for a Bookstore system.
Let’s start by coding the Model module. We will create a Book class, to represent books from the system.
The code for the class is shown bellow:
package com.alexandreesl.model;
public class Book {
private Long id;
private String name;
private String author;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
}
Then, we modify the module, to expose the model class:
module com.alexandreesl.model {
exports com.alexandreesl.model;
}
Next, we code the DAO module. We will create a interface and implementation for the module, separating each other by package segregation. We will also create a object factory.
This is the code for the interface, implementation and object factory of the dao module:
package com.alexandreesl.dao.interfaces;
import com.alexandreesl.model.Book;
public interface IBookDAO {
void create(Book book);
void update(Book book);
Book find(Long id);
}
package com.alexandreesl.dao.impl;
import com.alexandreesl.dao.IBookDAO;
import com.alexandreesl.model.Book;
public class BookDAOImpl implements IBookDAO {
@Override
public void create(Book book) {
System.out.println("INSERTED THE BOOK!");
}
@Override
public void update(Book book) {
System.out.println("UPDATED THE BOOK!");
}
@Override
public Book find(Long id) {
Book book = new Book();
book.setId(id);
book.setName("Elasticsearch: Consuming real-time data with ELK");
book.setAuthor("Alexandre Eleutério Santos Lourenço");
return book;
}
}
package com.alexandreesl.dao.interfaces;
import com.alexandreesl.dao.impl.BookDAOImpl;
public class BookDAOFactory {
public static IBookDAO getBookDAO() {
return new BookDAOImpl();
}
}
The image bellow shows the final structure of the model with the classes:
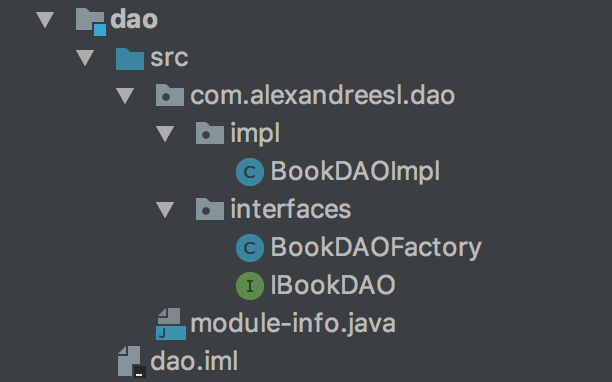
To expose the model and also use the Book class from the Model module, we add the following lines to the module definition:
module com.alexandreesl.dao {
requires com.alexandreesl.model;
exports com.alexandreesl.dao.interfaces;
}
Here we can see a important advantage of modules: since we didn’t exported the impl package, the implementation won’t be exposed to code outside the module.
Now we code the service module. To simplify things up, we won’t create a interface-implementation approach this time, just a delegation class to the DAO layer. The code for the service class is shown bellow:
package com.alexandreesl.service;
import com.alexandreesl.dao.interfaces.BookDAOFactory;
import com.alexandreesl.dao.interfaces.IBookDAO;
import com.alexandreesl.model.Book;
public class BookService {
private IBookDAO bookDAO;
public BookService() {
bookDAO = BookDAOFactory.getBookDAO();
}
public void create(Book book) {
bookDAO.create(book);
}
public void update(Book book) {
bookDAO.update(book);
}
public Book find(Long id) {
return bookDAO.find(id);
}
}
And the module changes are as follows:
module com.alexandreesl.service {
requires com.alexandreesl.model;
requires com.alexandreesl.dao;
exports com.alexandreesl.service;
}
Finally, we code the main module, that it is simply a main method where we test it out our structure:
package com.alexandreesl.application;
import com.alexandreesl.model.Book;
import com.alexandreesl.service.BookService;
public class Main {
public static void main(String[] args) {
Book book = new Book();
book.setAuthor("Stephen King");
book.setId(1l);
book.setName("IT - The thing");
BookService service = new BookService();
service.create(book);
book.setName("IT");
service.update(book);
Book searchedBook = service.find(2l);
System.out.println(searchedBook.getName());
System.out.println(searchedBook.getAuthor());
}
}
If we run our code, we will see that everything works, just as designed:
/Library/Java/JavaVirtualMachines/jdk-9.jdk/Contents/Home/bin/java "-javaagent:/Applications/IntelliJ IDEA CE.app/Contents/lib/idea_rt.jar=50683:/Applications/IntelliJ IDEA CE.app/Contents/bin" -Dfile.encoding=UTF-8 -p /Users/alexandrelourenco/Applications/git/JigsawLab9/out/production/application:/Users/alexandrelourenco/Applications/git/JigsawLab9/out/production/service:/Users/alexandrelourenco/Applications/git/JigsawLab9/out/production/dao:/Users/alexandrelourenco/Applications/git/JigsawLab9/out/production/model -m com.alexandreesl.application/com.alexandreesl.application.Main INSERTED THE BOOK! UPDATED THE BOOK! Elasticsearch: Consuming real-time data with ELK Alexandre Eleutério Santos Lourenço Process finished with exit code 0
Please remember that, if the reader wants it, the code of this project is on Github, on this link.
Static dependencies
One thing that the reader may notice from our code, is that we needed to import the model module on each of the other modules of our system. This is because, as said before, no dependency required by a module is automatically inherited by another module on the hierarchy. All the requirements must be explicit declared to be linked.
However, on this case, if we wanted to declare the dependency on just one module and tell Java on the other modules that the dependency will be met later, we could use the static keyword. Static dependencies on Jigsaw are analogous to the provided scope on Maven, where a dependency is marked just for compilation requirements and it is assumed will be there when the code runs.
To make the changes so the model module is imported on just one module, we change all module definitions to the following:
module com.alexandreesl.application {
requires com.alexandreesl.model;
requires com.alexandreesl.service;
}
module com.alexandreesl.dao {
requires static com.alexandreesl.model;
exports com.alexandreesl.dao.interfaces;
}
module com.alexandreesl.service {
requires static com.alexandreesl.model;
requires com.alexandreesl.dao;
exports com.alexandreesl.service;
}
If we run again our code, we will see that it runs successfully, just like before.
Package manager support
Since it is a new concept introduced just now, there is still some work undergoing on Java’s package management frameworks, such as Maven and Gradle. Keep it in mind that the objective of Jigsaw is not to replace package management systems.
Think of it more of a complement to this systems, with Jigsaw managing exposure and internal dependencies and the package systems managing issues such as packaging artifacts, running tests, etc.
If the reader is familiar with Gradle, there is some plugins already developed that integrates Jigsaw with it, like chainsaw:
https://github.com/zyxist/chainsaw
Conclusion
And so we conclude our Java 9 series. With several interesting new features, this new edition of Java proves not only that Java has still some relevance on the market, but also can still be evolved with the most modern practices on use. Thank you for following me on this post, until next time.