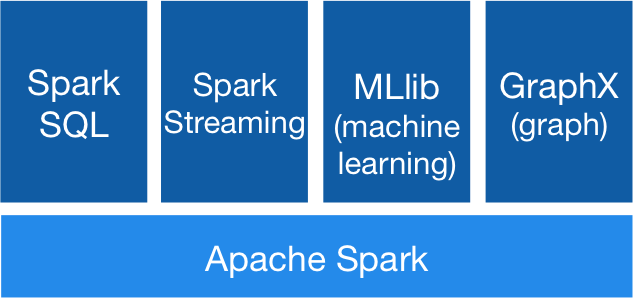
Welcome, dear reader, to the last post in our series on Big Data. If the reader has not read the previous posts in this series, the links can be found at the end of this post, or in the menus, “Big Data” section. In this final post, we will discuss some interesting cases in the use of Big Data in order to demonstrate how it has been used by the market. If the reader wants to know more about any case in particular, the reference links to them can be found at the end of this post.
HealthMap: preventing diseases
Driven by the need to monitor the progress of epidemics around the world, the HealthMap tool was created by researchers in Boston. It uses various data sources such as social media, local news, etc in order to predict the progress of the diseases across the globe. The tool was highlighted in the media recently as predicted the emergence of Ebola in Guinea nine days before the WHO announcement.
Google: better efficience on the data sources
Possessing the world’s largest search engine, and other solutions such as cloud computing, Google has huge data centers to support its operation. Through a Big Data solution that collects various information such as power consumption, temperature, CPU power, memory, etc, was possible to establish a quickly number of measures that improved the performance of the data center, such as adjustments in the cooling system, thereby preventing temperature peaks that compromise the performance of the equipment, and increases energy consumption.
Target: predicting consumer behavior
Target retail company, with branches in several countries such as USA and Australia, has implemented an interest case of Big Data. Using sales data and navigation of its customers, extracted through its channels such as E-Commerce, the retailer can trace their customers behavior, providing what products they would be more interested in purchasing. Gained prominence in the media predicting the products to offer for pregnant women, where through the purchases of a customer, the solution detects that it is a pregnant women and through promotional email offers for the products that will be interested in acquiring on the next week of pregnancy.
Ford: vehicle real-time analysis
The famous car manufacturer has implemented a Big Data solution very innovative, which involves collecting data from customers’ own cars in real time. Through sensors, data of the engine and other parts of the cars are sent in real time to Ford’s data centers, which use the data for applications such as the correction of design engineering of future releases, preventive maintenance and offers greater flexibility in recalls detection.
Conclusion
And so, we conclude our first journey in the world of Big Data. It is clear, however, that we will not stop here: I promise the reader to continue evolving our studies in Big Data. Please be sure to follow my blog, where I intend to start a series of hands-on, where we will see more of the key technologies associated with Big Data put it in practice. I thank all who have accompanied me in this series and I wish you all much success in your careers, whether in the world of big data or not. Thank you