

Welcome, dear reader, to another post in our series on Big Data. If the reader has not read the previous posts in this series, the links can be found at the end of this post, or in the menus, “Big Data” section. In this post, we will cover a technology that has gained quite popularity in the world of Big Data: The Apache Spark.
Origin
Created in Berkeley University by AMPLab, the goal of Spark is to provide a computer model, according to the official website, up to 100x faster than a conventional mapreduce Hadoop job. But how it hopes to achieve this performance improvement?
Architecture
Such gain is based on this one point in Hadoop mapreduce model. During the execution of a Hadoop job, we have 3 times when the data is “stored” in the processing:
- At initial processing, before the map step;
- In the midst of processing, when the data filtered by the map phase is being stored for later stages of sort and reduce;
- At the end of the processing, when the final result is delivered;
In Hadoop, on these three aforementioned moments, we have an IO disk consumption, because the data is stored on disk, rather than kept in memory, including the intermediate step between the steps of map and reduce. In a production environment of Big Data, it is common to have iterative jobs, running several times on a given body of data, using the result of the previous run as input for the next run. It is precisely in this scenario that the Spark has its biggest gain: keeping the data in memory, the access / write of the data becomes much faster, thus ensuring the announced earnings. From this seemingly simple change, the Spark project, which allows constructing jobs following the BSP model (Bulk Synchronous Parallel), was born keeping as much as possible of the data in memory within a run, thus ensuring a fast and scalable computational model. In the picture below we can see the architecture of the Spark and its subprojects, which we will discuss below
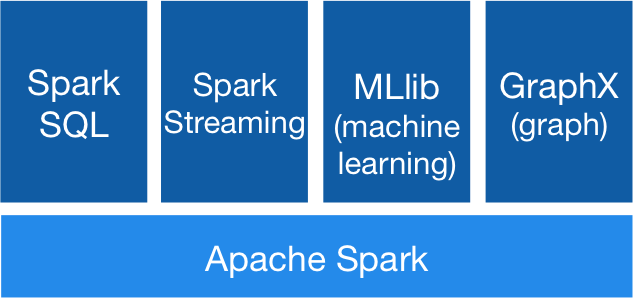 Complementary modules
Complementary modules
From the Spark initial project, 4 subprojects were born, that complement his use. All these modules are already part of the default installation of Spark and they are:
Spark SQL: Similar to what is the Hive for Hadoop, Spark SQL brings a language similar to SQL for data query on a Spark installation;
Spark Streaming: Spark streaming allows the build of streaming style applications, where the data can be read / written during the processing, instead of the traditional model, where results from a process can only be delivered at the end of a execution;
MLlib: Equivalent to Apache Mahout, allows the construction of machine learning processes. Machine learning is a field within computer science, where using of statistical and logical rules, programs can “learn” and draw your own conclusions from a mass of data provided as input, simulating a human reasoning;
GraphX: The Spark GraphX allows processing to be built in the Graph format, allowing the resolution of problems through algorithms like Pert, BFS and DFS.
Spark & Hadoop
The reader may be wondering at this point: may I use Spark or Hadoop in my Big Data project? Like everything in the world of technology, this is no simple answer. Several factors may influence this decision, not only technical, but also business, such as the absence, to date, of major players that provide distributions with commercial support, unlike Hadoop that already has commercial distributions of weight as Cloudera and Hortonworks. Due to his complementary nature – Spark integrates with most of the components that make up Hadoop – however, it is possible that Spark could go for a complementary technology over than a competing platform. An example of this is the distribution of Cloudera itself, which provides a Hadoop distribution that also has a Spark distribution. Thus, we have as an increasingly scenario, the combination of the two technologies, rather than using only one of the two. After all, why should we use only 1, if we can enjoy the best that each has to offer us?
Conclusion
And so we come to the conclusion of another chapter of our series. In the next and last post in our series, we will examine some cases of the use of Big Data in the world, in order that we see in practice all the benefits that the Big Data can offer us. Until next time.
Continue reading
