
Welcome, dear readers! Welcome to another post of my blog. On this post, we will talk about Hazelcast, a open source solution for in-memory data grids, used by companies such as AT&T, HSBC, Cisco and HP. But after all, why do we want to use a in-memory data grid?
In-memory Data Grids
In-memory data grids, also known as IMDGs, are distributed data structures, where the whole data is stored entirely on the RAM (Random Access Memory) across a cluster. This way, we could have both the advantages of using faster resources such as the RAM, opposed to the hard disk – off course, IMDGs such as HazelCast also use the hard disk as a persistent store for fault tolerance, but still, for the applications usage, the major resource is the RAM – and the horizontal scalability of a cluster, opposed to the traditional vertical scalability of a relational database, for example.
Common use case scenarios for IMDGs are as a caching layer for databases, clustering web sessions for web applications and even as NOSQL solutions.
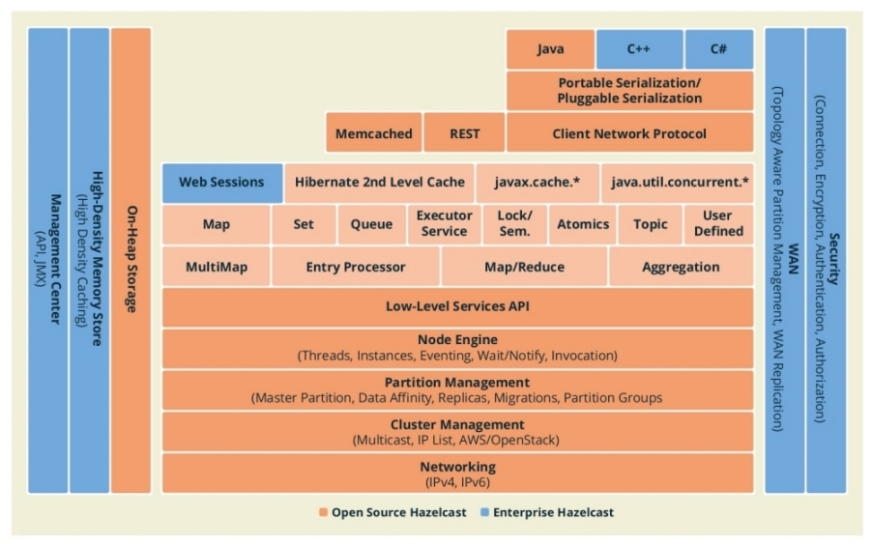
Talking about HazelCast, we have a very robust architecture, which provides features such as encryption, clustering replication and partitioning and more. The following picture, extracted from HazelCast’s documentation, shows the features from the architecture both on free and enterprise editions.
Installation & set up
HazelCast has a very simple installation, that basically consist of downloading a tar.gz and extracting his contents. In order to do this, we visit HazelCast’s download page and click on the tar.gz button – or zip, if the reader is using Windows, I am using Ubuntu 15.04 -, after the download, we extract the tar.gz on the folder of our preference and that’s it, we finished our installation! The only prior requisite is to have Java installed, which the reader can install downloading from here.
To start a HazelCast node, we simply start a shell script provided by the installation. On versions previous to 3.2.6, this script was called run.sh and was inside the bin folder. On newer versions, the script is called server.sh, but it is still inside the bin folder. So to start a node, simply navigate on a terminal to the folder we extracted previously – if the reader is using the same version I am using, it would be called hazelcast-3.4.2 – and type:
cd bin
./server.sh
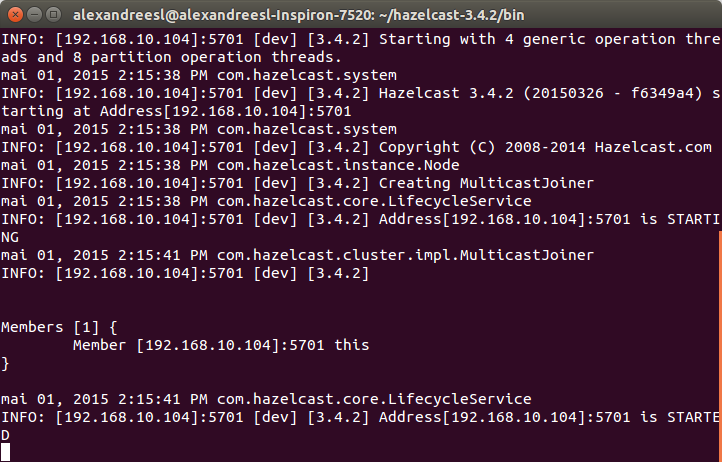
After some seconds, we can see that the node has successfully booted:
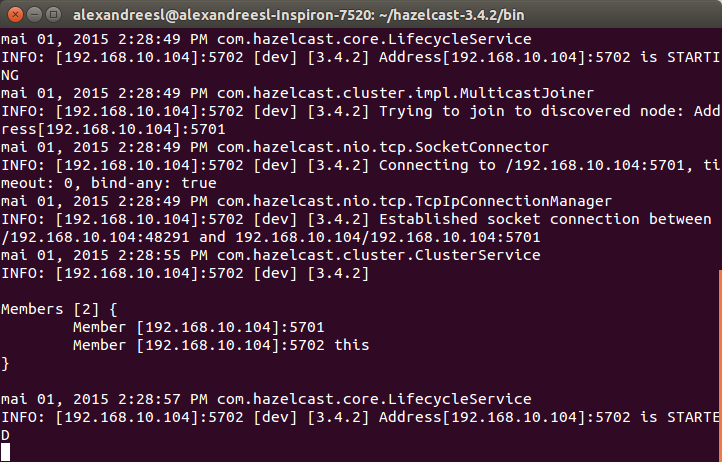
For this lab, we will use a HazelCast cluster composed of 3 nodes, so, we open another 2 terminal windows and repeat the previous procedure to start the first node. HazelCast uses multicast to check and establish the participation of new nodes on the cluster, as we can see on the members list updated by the nodes on their consoles, as we include new nodes:
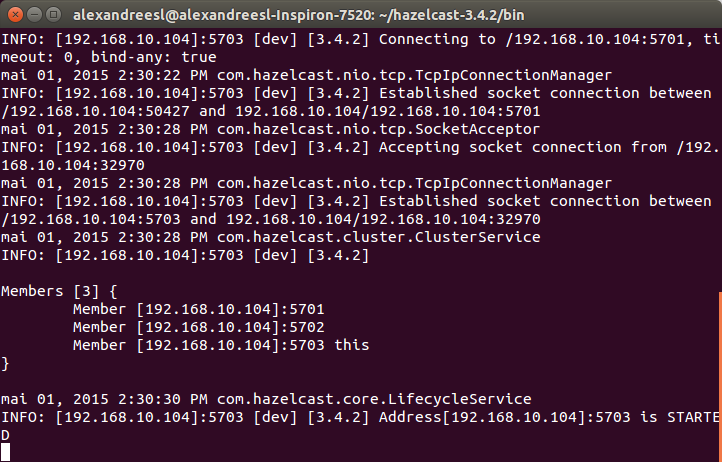
That’s all we need to do to create the cluster for our lab. Now, let’s start using HazelCast!
Using distributed objects
To connect to our HazelCast cluster, there’s 3 ways:
- Programmatic configuration, by using the classes of the Java API;
- By XML configuration, using a XML called hazelcast.xml that we put on the classpath;
- By integrating HazelCast with Spring;
On this lab, we will explore the first option, so, starting our lab, let’s create a new Maven project – without adding any archetype – and include the following dependencies on the pom.xml:
.
.
.
<dependencies>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>3.4.2</version>
</dependency><dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-client</artifactId>
<version>3.4.2</version>
</dependency></dependencies>
.
.
.
After including the dependencies, let’s create a class, responsible for creating a single HazelCast’s instance for us, for reuse on the whole application:
public class HazelCastFactory {
private static HazelcastInstance cluster;
private static boolean shutDown = true;
public static HazelcastInstance getInstance() {
if (shutDown) {
ClientConfig clientConfig = new ClientConfig();
ClientNetworkConfig clientNetworkConfig = new ClientNetworkConfig();
clientNetworkConfig.addAddress(“127.0.0.1:5701”);
clientConfig.setNetworkConfig(clientNetworkConfig);
cluster = HazelcastClient.newHazelcastClient(clientConfig);
shutDown = false;}
return cluster;
}
public static void shutDown() {
cluster.shutdown();
shutDown = true;
}}
On the code above we created a client to connect to our HazelCast’s cluster, pointing the node on the 5701 port as the entry point of our connection. If we want to add other addresses for cases in which our entry node falls on the connection start, we just add more addresses with the addAddress method. There’s no need to add the whole cluster to use the data grid, however: HazelCast itself is responsible for load balancing the requests across the cluster. We also included a method to shutdown our connection to the data grid, releasing the resources allocated.
NOTE: One interesting thing to note is that, when a client connects to a HazelCast cluster, he actually establish a connection to the cluster, not just the node we informed as the entry point, meaning that, even if the entry node falls after the connection is established, our client will still maintain a connection with the cluster.
Let’s begin by creating a distributed object on the cluster, a map data structure. Distributed objects are objects created and managed by the cluster, with their data distributed and replicated across the cluster.
To create it, all we have to do is call the getMap mehod on the client instance we receive from the factory class, providing a unique name on the cluster to identify the map:
public class HazelCastDistributedMap {
public static void main(String[] args) {
HazelcastInstance client = HazelCastFactory.getInstance();
Map<String, String> map = client.getMap(“mymap”);
HazelCastFactory.shutDown();
}
}
As we can see, is very simple to create a map. To use it, is even more simple: all we have to do is use the methods from the Map interface, just like we do with any basic Map on a common Java program. Behind the scenes, HazelCast is working for us, supplying a IMDG for our data. Let’s demonstrate this by creating a more elaborated example. First, we create a POJO, representing a client (NOTE: in order to be distributed by HazelCast, the objects used must be serializable):
public class Client implements Serializable {
/**
*
*/
private static final long serialVersionUID = -4870061854652654067L;private String name;
private Long phone;
private String sex;
public String getName() {
return name;
}public void setName(String name) {
this.name = name;
}public Long getPhone() {
return phone;
}public void setPhone(Long phone) {
this.phone = phone;
}public String getSex() {
return sex;
}public void setSex(String sex) {
this.sex = sex;
}}
Then, we change the example to the following:
public class HazelCastDistributedMap {
public static void main(String[] args) {
HazelcastInstance client = HazelCastFactory.getInstance();
IMap<Long, Client> map = client.getMap(“customers”);
Client clientData = new Client();
clientData.setName(“Alexandre Eleuterio Santos Lourenco”);
clientData.setPhone(33455676l);
clientData.setSex(“M”);map.put(clientData.getPhone(), clientData, 5, TimeUnit.MINUTES);
clientData = new Client();
clientData.setName(“Lucebiane Santos Lourenco”);
clientData.setPhone(456782387l);
clientData.setSex(“F”);map.put(clientData.getPhone(), clientData, 2, TimeUnit.MINUTES);
clientData = new Client();
clientData.setName(“Ana Carolina Fernandes do Sim”);
clientData.setPhone(345622189l);
clientData.setSex(“F”);map.put(clientData.getPhone(), clientData, 120, TimeUnit.SECONDS);
HazelCastFactory.shutDown();
client = HazelCastFactory.getInstance();
Map<Long, Client> mapPostShutDown = client.getMap(“customers”);
for (Long phone : mapPostShutDown.keySet()) {
Client cli = mapPostShutDown.get(phone);System.out.println(cli.getName());
}
System.out.println(mapPostShutDown.size());
HazelCastFactory.shutDown();
}
}
As we can see on the new code, we obtained a distributed map from HazelCast, inserted some clients on it, shutdown the connection, reopened and finally iterated by the map, printing the names of the clients and the size of the map. If we run the code, we will receive, alongside logging information from the HazelCast’s client, the following prints:
Ana Carolina Fernandes do Sim
Alexandre Eleuterio Santos Lourenco
Lucebiane Santos Lourenco
3
If we revisit the code, two things are noticeable: First, we used a put method which received alongside the key and value, another 2 parameters. The two last parameters we used on the put method are the time-to-live (TTL), which can be set individually like we did previously, or in a global fashion, using the Configuration classes we used on our factory class. The other thing we can notice is that we got our map from HazelCast’s client first with the IMap interface from HazelCast and secondly with the plain classic java.util.Map. The IMap interface provide us with other features alongside the traditional ones from a map such as listeners to be executed at every put/get/delete action on the map or even a processor to be executed for a certain key or even all the keys. On the next sections, we will see examples of both of this features. This interface also implements the Map interface, reason why we can also get our map from HazelCast as a java.util.Map.
One thing that it is very important to notice is that, after we retrieve a value from a map already stored on HazelCast, the object is not updated on the cluster. Let’s see a example to understand in better detail the implications of this behavior. Let’s analyse if we change our code to the following:
.
.
.
clientData = new Client();
clientData.setName(“Ana Carolina Fernandes do Sim”);
clientData.setPhone(345622189l);
clientData.setSex(“F”);map.put(clientData.getPhone(), clientData, 120, TimeUnit.SECONDS);
clientData = (Client) map.get(33455676l);
clientData.setName(“Alexandre Eleuterio Santos Lourenco UPDATED!”);
HazelCastFactory.shutDown();
client = HazelCastFactory.getInstance();
.
.
.
If we run this code, we will see that the client we tried to update before we shutdown our connection for the first time won’t be updated. The reason for this is that objects already stored on HazelCast aren’t re-serialized if we make changes on them, unless we explicit do this, by re-inputing the data on the map. To do this, we change our code for the following:
public class HazelCastDistributedMap {
public static void main(String[] args) {
HazelcastInstance client = HazelCastFactory.getInstance();
IMap<Long, Client> map = client.getMap(“customers”);
Client clientData = new Client();
clientData.setName(“Alexandre Eleuterio Santos Lourenco”);
clientData.setPhone(33455676l);
clientData.setSex(“M”);map.put(clientData.getPhone(), clientData, 5, TimeUnit.MINUTES);
clientData = new Client();
clientData.setName(“Lucebiane Santos Lourenco”);
clientData.setPhone(456782387l);
clientData.setSex(“F”);map.put(clientData.getPhone(), clientData, 2, TimeUnit.MINUTES);
clientData = new Client();
clientData.setName(“Ana Carolina Fernandes do Sim”);
clientData.setPhone(345622189l);
clientData.setSex(“F”);map.put(clientData.getPhone(), clientData, 120, TimeUnit.SECONDS);
clientData = (Client) map.get(33455676l);
clientData.setName(“Alexandre Eleuterio Santos Lourenco UPDATED!”);
map.put(clientData.getPhone(), clientData, 5, TimeUnit.MINUTES);
HazelCastFactory.shutDown();
client = HazelCastFactory.getInstance();
Map<Long, Client> mapPostShutDown = client.getMap(“customers”);
for (Long phone : mapPostShutDown.keySet()) {
Client cli = mapPostShutDown.get(phone);System.out.println(cli.getName());
}
System.out.println(mapPostShutDown.size());
HazelCastFactory.shutDown();
}
}
If we run again the code and check the prints, we can see that now our client is correctly updated.
Listeners
Like we talked before, the IMap interface – and other interfaces from HazelCast’s API – allow us to use another features besides the traditional operations from a Java Collection, such as listeners. With listeners, we can create additional code to run every time a entry is added/updated/deleted/evicted (entries can be evicted automatically by a policy in order to maintain the cluster’s memory capabilities), or even when the whole map is evicted or cleared. In order to implement a listener to our Map, we use a interface called EntryListener and implement a class like the following:
public class MyMapEntryListener implements EntryListener<Long, Client> {
public void entryAdded(EntryEvent<Long, Client> event) {
System.out.println(“entryAdded:” + event);}
public void entryRemoved(EntryEvent<Long, Client> event) {
System.out.println(“entryRemoved:” + event);}
public void entryUpdated(EntryEvent<Long, Client> event) {
System.out.println(“entryUpdated:” + event);}
public void entryEvicted(EntryEvent<Long, Client> event) {
System.out.println(“entryEvicted:” + event);}
public void mapEvicted(MapEvent event) {
System.out.println(“mapEvicted:” + event);}
public void mapCleared(MapEvent event) {
System.out.println(“mapCleared:” + event);}
}
And finally, we add the listener to our map, like the following snippet:
.
.
.
HazelcastInstance client = HazelCastFactory.getInstance();
IMap<Long, Client> map = client.getMap(“customers”);
map.addEntryListener(new MyMapEntryListener(), true);
.
.
.
On the code above, we added the listener using the addEntryListener method. The second parameter, a boolean, is used to indicate if the event class we receive as parameter for the event’s methods should receive the entry’s value or not. If we run the code, we will see that among the messages on the console, we will receive outputs from our listener, like the following:
entryAdded:EntryEvent{entryEventType=ADDED, member=Member [192.168.10.104]:5702, name=’customers’, key=33455676, oldValue=null, value=com.alexandreesl.handson.model.Client@44daa124}
entryAdded:EntryEvent{entryEventType=ADDED, member=Member [192.168.10.104]:5702, name=’customers’, key=456782387, oldValue=null, value=com.alexandreesl.handson.model.Client@588ec3d1}
entryAdded:EntryEvent{entryEventType=ADDED, member=Member [192.168.10.104]:5702, name=’customers’, key=345622189, oldValue=null, value=com.alexandreesl.handson.model.Client@4476e1bd}
entryUpdated:EntryEvent{entryEventType=UPDATED, member=Member [192.168.10.104]:5702, name=’customers’, key=33455676, oldValue=com.alexandreesl.handson.model.Client@63a68758, value=com.alexandreesl.handson.model.Client@1f5df98a}
One important thing to note about the EntryListener, is HazelCast’s threading system. If we include a sysout to print the current thread on our listener – I included on the add and update entries methods, since are the ones we are using on our examples – we can see that the executions are asynchronous, since HazelCast creates a thread pool to serve the listener calls. The following snippet from the console shows this behavior:
thread:hz.client_0_dev.event-2
thread:hz.client_0_dev.event-1
entryUpdated:EntryEvent{entryEventType=UPDATED, member=Member [192.168.10.104]:5702, name=’customers’, key=33455676, oldValue=com.alexandreesl.handson.model.Client@63a68758, value=com.alexandreesl.handson.model.Client@1f5df98a}
entryUpdated:EntryEvent{entryEventType=UPDATED, member=Member [192.168.10.104]:5702, name=’customers’, key=456782387, oldValue=com.alexandreesl.handson.model.Client@588ec3d1, value=com.alexandreesl.handson.model.Client@564936b0}
thread:hz.client_0_dev.event-3
entryUpdated:EntryEvent{entryEventType=UPDATED, member=Member [192.168.10.104]:5702, name=’customers’, key=345622189, oldValue=com.alexandreesl.handson.model.Client@4ab1169b, value=com.alexandreesl.handson.model.Client@4476e1bd}
thread:hz.client_0_dev.event-2
entryUpdated:EntryEvent{entryEventType=UPDATED, member=Member [192.168.10.104]:5702, name=’customers’, key=33455676, oldValue=com.alexandreesl.handson.model.Client@1f4f3962, value=com.alexandreesl.handson.model.Client@e8d682e}
With that being said, one thing is important to keep a eye out when using this feature: according to HazelCast’s documentation, this thread pool is exclusive for the execution of the events, not been shared with the thread that execute the action itself – meaning that, even if we run our examples creating the node on the main method, running the node embedded on our program, instead of connecting to a remote cluster, still the thread that runs our event won’t be the same that manipulate the data – so if we create too much logic to run with our listener, we can run on a situation that some of the calls to the listener would fail, because there would be no threads available to run the listener.
Processors
Another feature we talked about previously is Processors. With a processor, we can add logic that we want to run to a single key on our map, or even all keys. One very important thing to notice in this feature, opposed to the listener one, is that this feature is scalable, because not only it runs on the server side, but it is also sent to all nodes of the cluster, executing the logic on all entries of the map, if applicable, on parallel. Let’s get a example where we want to change all the phones of our clients to “888888888”. To do this, we implement the following class to accomplish this task:
public class MyMapProcessor extends AbstractEntryProcessor<String, Client> {
/**
*
*/
private static final long serialVersionUID = 8890058180314253853L;@Override
public Object process(Entry<String, Client> entry) {Client client = entry.getValue();
client.setPhone(888888888l);
entry.setValue(client);
System.out.println(“Processing the client: ” + client.getName());
return null;
}}
And finally, in order to test our processor, we change the code of our main class to the following:
.
.
.
IMap<Long, Client> mapProcessors = client.getMap(“customers”);
mapProcessors.executeOnEntries(new MyMapProcessor());
HazelCastFactory.shutDown();
client = HazelCastFactory.getInstance();
mapProcessors = client.getMap(“customers”);
for (Long phone : mapProcessors.keySet()) {
Client cli = mapProcessors.get(phone);System.out.println(cli.getName() + ” ” + cli.getPhone());
}
.
.
.
However, if we run our code the way it is, we will be greeted with the following error:
Exception in thread “main” com.hazelcast.nio.serialization.HazelcastSerializationException: java.lang.ClassNotFoundException: com.alexandreesl.handson.examples.MyMapProcessor
at com.hazelcast.nio.serialization.DefaultSerializers$ObjectSerializer.read(DefaultSerializers.java:201)
at com.hazelcast.nio.serialization.StreamSerializerAdapter.read(StreamSerializerAdapter.java:44)
at com.hazelcast.nio.serialization.SerializationServiceImpl.readObject(SerializationServiceImpl.java:309)
at com.hazelcast.nio.serialization.ByteArrayObjectDataInput.readObject(ByteArrayObjectDataInput.java:439)
at com.hazelcast.map.impl.client.MapExecuteOnAllKeysRequest.read(MapExecuteOnAllKeysRequest.java:96)
at com.hazelcast.client.impl.client.ClientRequest.readPortable(ClientRequest.java:116)
at com.hazelcast.nio.serialization.PortableSerializer.read(PortableSerializer.java:88)
at com.hazelcast.nio.serialization.PortableSerializer.read(PortableSerializer.java:30)
at com.hazelcast.nio.serialization.StreamSerializerAdapter.toObject(StreamSerializerAdapter.java:65)
at com.hazelcast.nio.serialization.SerializationServiceImpl.toObject(SerializationServiceImpl.java:260)
at com.hazelcast.client.impl.ClientEngineImpl$ClientPacketProcessor.loadRequest(ClientEngineImpl.java:364)
at com.hazelcast.client.impl.ClientEngineImpl$ClientPacketProcessor.run(ClientEngineImpl.java:340)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
at com.hazelcast.util.executor.HazelcastManagedThread.executeRun(HazelcastManagedThread.java:76)
at com.hazelcast.util.executor.HazelcastManagedThread.run(HazelcastManagedThread.java:92)
at —— End remote and begin local stack-trace ——.(Unknown Source)
at com.hazelcast.client.spi.impl.ClientCallFuture.resolveResponse(ClientCallFuture.java:202)
at com.hazelcast.client.spi.impl.ClientCallFuture.get(ClientCallFuture.java:143)
at com.hazelcast.client.spi.impl.ClientCallFuture.get(ClientCallFuture.java:119)
at com.hazelcast.client.spi.ClientProxy.invoke(ClientProxy.java:151)
at com.hazelcast.client.proxy.ClientMapProxy.executeOnEntries(ClientMapProxy.java:890)
at com.alexandreesl.handson.examples.HazelCastDistributedMap.main(HazelCastDistributedMap.java:68)
Caused by: java.lang.ClassNotFoundException: com.alexandreesl.handson.examples.MyMapProcessor
at java.net.URLClassLoader$1.run(URLClassLoader.java:372)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361).
.
.
The reason for this is because we don’t have the class on the classpath of our cluster. In order to resolve this, first we will export both the Client and the MyMapProcessor classes on a jar – the reader can obtain a jar already prepared by me on the github repository at the end of this post -, save the jar on the lib folder of HazelCast´s installation folder and edit the classpath on the server.sh script on the bin folder of HazelCast:
.
.
.
export CLASSPATH=$HAZELCAST_HOME/lib/hazelcast-3.4.2.jar:$HAZELCAST_HOME/lib/hazelcastcustomprocessors.jar
.
.
.
After restarting our cluster, we can see on the console that all the clients have the same phone, proving that our processor was successful:
Ana Carolina Fernandes do Sim 888888888
Alexandre Eleuterio Santos Lourenco UPDATED! 888888888
Lucebiane Santos Lourenco 888888888
Out of curiosity, one last thing to notice is that, as we have also coded a sysout on our processor, we can search the console of our nodes and see that our sysouts are printed there, like in the screen bellow:
NOTE: According to HazelCast´s documentation, it is a good practice to isolate all the classes shared across client and server – in our case, our HazelCast´s client and the cluster itself – in a separate project, making the structure less coupled.
MultiMaps
One last feature we are going to visit is the multimaps. Sometimes, we would like to store multiple values for a single key, like storing a list of orders by user id, for example. On a simple solution, we could simply use a common map and pass for the value parameter as a Collection, like a List or a Set. However, when using this approach on a distributed system, this would lead to 2 problems:
- Performance: when using a distributed system, the whole value is serialized and deserialized before the operations are made. That means that if we have a list with 50 items on the value, for example, every time we want to include a new value to the list, the whole list will be deserialized, the new value included and the whole list be reserialized again! Of course, this leads to a overhead, which in turn affects the performance of our map;
- Thread safety: when using the common implementation of the map collection, there is no concurrency controls implemented on his methods. That means that if we are using a common map with a collection as the value and we have multiple consumers updating the values, we could run with problems of concurrency, such as values not being updated or even removed;
In order to address this problems, HazelCast provides us with a special implementation called Multimap. To illustrate the use of the implementation, let’s create a class called HazelCastDistributedMultiMap and code it like the following:
public class HazelCastDistributedMultiMap {
public static void main(String[] args) {
HazelcastInstance client = HazelCastFactory.getInstance();
MultiMap<String, Client> map = client.getMultiMap(“multicustomers”);
Client clientData = new Client();
clientData.setName(“Alexandre Eleuterio Santos Lourenco”);
clientData.setPhone(33455676l);
clientData.setSex(“M”);map.put(clientData.getSex(), clientData);
clientData = new Client();
clientData.setName(“Lucebiane Santos Lourenco”);
clientData.setPhone(456782387l);
clientData.setSex(“F”);map.put(clientData.getSex(), clientData);
clientData = new Client();
clientData.setName(“Ana Carolina Fernandes do Sim”);
clientData.setPhone(345622189l);
clientData.setSex(“F”);map.put(clientData.getSex(), clientData);
HazelCastFactory.shutDown();
client = HazelCastFactory.getInstance();
map = client.getMultiMap(“multicustomers”);
for (String key : map.keySet()) {
for (Client cli : map.get(key)) {
System.out.println(“The Client: ” + cli.getName()
+ ” for the Key: ” + key);}
}
HazelCastFactory.shutDown();
}
}
If we run the code, we can see by the sysouts that HazelCast has successfully grouped the clients by the sex, proving that our code was a success:
The Client: Alexandre Eleuterio Santos Lourenco for the Key: M
The Client: Ana Carolina Fernandes do Sim for the Key: F
The Client: Lucebiane Santos Lourenco for the Key: F
Other features
Of course, there is much more HazelCast is capable of alongside what we see on this post, like the ability to work with primitives on the cluster, implement asynchronous solutions with queues and topics and even a criteria API that enable us to search our data on a “JPA-like” fashion. On the links section, there is a link for a PDF called Mastering HazelCast, made by HazelCast themselves, which is free and a very good source of information to get more deep on all the subjects about HazelCast.
Conclusion
And this concludes another post. With the advances of the hardware technologies, it became more and more easy to develop solutions entirely on pure RAM and/or with a very heavy usage of parallelism, such as Big Data´s related technologies. In time, distributed systems will became so common – and in a sense, they already are – that one day we will wonder how we lived before them! Thank you for following me on another post, until next time.
