Hi, dear readers! Welcome to my blog. On this post, we will talk about Apache Camel, a robust solution for deploying system integrations across various technologies, such as REST, WS, JMS, JDBC, AWS Products, LDAP, SMTP, Elasticsearch etc.
So, let’s get start!
Origin
Apache Camel was created on Apache Service Mix. Apache Service Mix was a project powered by the Spring Framework and implemented following the JBI specification. The Java Business Integration specification specifies a plug and play platform for systems integrations, following the EIP (Enterprise Integration Patterns) patterns.
Terminology
Exchange
Exchanges – or MEPs(Message Exchange Patterns) – are like frames where we transport our data across the integrations on Camel. A Exchange can have 2 messages inside, one representing the input and another one representing the output of a integration.
The output message on Camel is optional, since we could have a integration that doesn’t have a response. Also, a Exchange can have properties, represented as key-value entries, that can be used as data that will be used across the whole route (we will see more about routes very soon)
Message
Messages are the data itself that is transferred inside a Camel route. A Message can have a body, which is the data itself and headers, which are, like properties on a Exchange, key-value entries that can be used along the processing.
One important aspect to keep in mind, however, is that along a Camel route our Messages are changed – when we convert the body with a Type converter, for instance – and when this happens, we lose all our headers. So, Message headers must be seen as ephemeral data, that will not be used through the whole route. For that type of data, it is better to use Exchange properties.
The Message body can de made of several types of data, such as binaries, JSON, etc.
Camel context
The Camel context is the runtime container where Camel runs it. It initializes type converters, routes, endpoints, EIPs etc.
A Camel context has 3 possible status: started, suspended and stopped. When started, the context will serve the routes processing as normal.
When on suspended status, the Camel context will stop the processing – after the Exchanges already on processing are completed – , but keep all the caches, resources etc still loaded. A suspended context can be restarted.
Finally, there’s the stop status. When stopped, the context will stop the processing like the suspended status, but also will release all the resources caches etc, making a complete shutdown. As with the suspended status, Camel will also guarantee that all the Exchanges being processing will be finished before the shutdown.
Route
Routes on Camel are the heart of the processing. It consists of a flow, that start on a endpoint, pass through a stream of processors/convertors and finishes on another endpoint. it is possible to chain routes by calling another route as the final endpoint of a previous route.
A route can also use other features, such as EIPs, asynchronous and parallel processing.
Channel
When Camel executes a route, the controller in which it executes the route is called Channel.
A Channel is responsible for chaining the processors execution, passing the Exchange from one to another, alongside monitoring the route execution. It also allow us to implement interceptors to run any logic on some route’s events, such as when a Exchange is going to a specific Endpoint.
Processor
Processors are the primary extension points on Camel. By creating classes that extend the org.apache.camel.Processor interface, we create programming units that we can use to include our own code on a Camel route, inside a convenient execute method.
Component
A Component act like a factory to instantiate Endpoints for our use. We don’t directly use a Component, we reference instead by defining a Endpoint URI, that makes Camel infer about the Component that it needs to be using in order to create the Endpoint.
Camel provides dozens of Components, from file to JMS, AWS Connections to their products and so on.
Registry
In order to utilize beans from IoC systems, such as OSGi, Spring and JNDI, Camel supplies us with a Bean Registry. The Registry’s mission is to supply the beans referred on Camel routes with the ones create on his associated context, such as a OSGi container, a Spring context etc
Type converter
Type converters, as the name implies, are used in order to convert the body of a message from one type to another. The uses for a converter are varied, ranging from converting a binary format to a String to converting XML to JSON.
We can create our own Type Converter by extending the org.apache.camel.TypeConverter interface. After creating our own Converter by extending the interface, we need to register it on the Type’s Converter Registry.
Endpoint
A Endpoint is the entity responsible for communicating a Camel Route in or out of his execution process. It comprises several types of sources and destinations as mentioned before, such as SQS, files, Relational Databases and so on. A Endpoint is instantiated and configured by providing a URI to a Camel Route, following the pattern below:
component:option?option1=value1&option2=value2
We can create our own Components by extending the org.apache.camel.Endpoint interface. When extending the interface, we need to override 3 methods, where we supply the logic to create a polling consumer Endpoint, a passive consumer Endpoint and a producer Endpoint.
Lab
So, without further delay, let’s start our lab! On this lab, we will create a route that polls access files from a access log style file, sends the logs to a SQS and backups the file on a S3.
Setup
The setup for our lab is pretty simple: It is a Spring Boot application, configured to work with Camel. Our Gradle.build file is as follows:
apply plugin: 'java'
apply plugin: 'eclipse'
apply plugin: 'org.springframework.boot'
apply plugin: 'maven'
apply plugin: 'idea'
jar {
baseName = 'apache-camel-handson'
version = '1.0'
}
project.ext {
springBootVersion = '1.5.4.RELEASE'
camelVersion = '2.18.3'
}
sourceCompatibility = 1.8
targetCompatibility = 1.8
repositories {
mavenLocal()
mavenCentral()
}
bootRun {
systemProperties = System.properties
}
dependencies {
compile group: 'org.apache.camel', name: 'camel-spring-boot-starter', version: camelVersion
compile group: 'org.apache.camel', name: 'camel-commands-spring-boot', version: camelVersion
compile group: 'org.apache.camel',name: 'camel-aws', version: camelVersion
compile group: 'org.apache.camel',name: 'camel-mail', version: camelVersion
compile group: 'org.springframework.boot', name: 'spring-boot-autoconfigure', version: springBootVersion
}
group 'com.alexandreesl.handson'
version '1.0'
buildscript {
repositories {
mavenLocal()
maven {
url "https://plugins.gradle.org/m2/"
}
mavenCentral()
}
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:1.5.4.RELEASE")
}
}
And the Java main file is a simple Java Spring Boot Application file, as follows:
package com.alexandreesl.handson;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
/**
* Created by alexandrelourenco on 28/06/17.
*/
@ComponentScan(basePackages = {"com.alexandreesl.handson"})
@SpringBootApplication
@EnableAutoConfiguration
public class ApacheCamelHandsonApp {
public static void main(String[] args) {
SpringApplication.run(ApacheCamelHandsonApp.class, args);
}
}
We also configure a configuration class, where we will register a type converter that we will create on the next section:
package com.alexandreesl.handson.configuration;
import org.apache.camel.CamelContext;
import org.apache.camel.spring.boot.CamelContextConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CamelConfiguration {
@Bean
public CamelContextConfiguration camelContextConfiguration() {
return new CamelContextConfiguration() {
@Override
public void beforeApplicationStart(CamelContext camelContext) {
}
@Override
public void afterApplicationStart(CamelContext camelContext) {
}
};
}
}
We also create a configuration which will create a AmazonS3Client and AmazonSQSClient, that will be used by the AWS-S3 and AWS-SQS Camel endpoints:
package com.alexandreesl.handson.configuration;
import com.amazonaws.auth.BasicAWSCredentials;
import com.amazonaws.internal.StaticCredentialsProvider;
import com.amazonaws.regions.Regions;
import com.amazonaws.services.s3.AmazonS3Client;
import com.amazonaws.services.sqs.AmazonSQSClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;
@Configuration
public class AWSConfiguration {
@Autowired
private Environment environment;
@Bean(name = "s3Client")
public AmazonS3Client s3Client() {
return new AmazonS3Client(staticCredentialsProvider()).withRegion(Regions.fromName("us-east-1"));
}
@Bean(name = "sqsClient")
public AmazonSQSClient sqsClient() {
return new AmazonSQSClient(staticCredentialsProvider()).withRegion(Regions.fromName("us-east-1"));
}
@Bean
public StaticCredentialsProvider staticCredentialsProvider() {
return new StaticCredentialsProvider(new BasicAWSCredentials("<access key>", "<secret access key>"));
}
}
PS: this lab assumes that the reader is familiar with AWS and already has a account. For the lab, a bucket called “apache-camel-handson” and a SQS called “MyInputQueue” were created.
Configuring the route
Now that we have our Camel environment set up, let’s begin creating our route. First, we create a type converter called “StringToAccessLogDTOConverter” with the following code:
package com.alexandreesl.handson.converters;
import com.alexandreesl.handson.dto.AccessLogDTO;
import org.apache.camel.Converter;
import org.apache.camel.TypeConverters;
import java.util.StringTokenizer;
/**
* Created by alexandrelourenco on 30/06/17.
*/
public class StringToAccessLogDTOConverter implements TypeConverters {
@Converter
public AccessLogDTO convert(String row) {
AccessLogDTO dto = new AccessLogDTO();
StringTokenizer tokens = new StringTokenizer(row);
dto.setIp(tokens.nextToken());
dto.setUrl(tokens.nextToken());
dto.setHttpMethod(tokens.nextToken());
dto.setDuration(Long.parseLong(tokens.nextToken()));
return dto;
}
}
Next, we change our Camel configuration, registering the converter:
package com.alexandreesl.handson.configuration;
import com.alexandreesl.handson.converters.StringToAccessLogDTOConverter;
import org.apache.camel.CamelContext;
import org.apache.camel.spring.boot.CamelContextConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CamelConfiguration {
@Bean
public CamelContextConfiguration camelContextConfiguration() {
return new CamelContextConfiguration() {
@Override
public void beforeApplicationStart(CamelContext camelContext) {
camelContext.getTypeConverterRegistry().addTypeConverters(new StringToAccessLogDTOConverter());
}
@Override
public void afterApplicationStart(CamelContext camelContext) {
}
};
}
}
Our converter reads a String and converts to a DTO, with the following attributes:
package com.alexandreesl.handson.dto;
/**
* Created by alexandrelourenco on 30/06/17.
*/
public class AccessLogDTO {
private String ip;
private String url;
private String httpMethod;
private long duration;
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getHttpMethod() {
return httpMethod;
}
public void setHttpMethod(String httpMethod) {
this.httpMethod = httpMethod;
}
public long getDuration() {
return duration;
}
public void setDuration(long duration) {
this.duration = duration;
}
@Override
public String toString() {
StringBuffer buffer = new StringBuffer();
buffer.append("[");
buffer.append(ip);
buffer.append(",");
buffer.append(url);
buffer.append(",");
buffer.append(httpMethod);
buffer.append(",");
buffer.append(duration);
buffer.append("]");
return buffer.toString();
}
}
Finally, we have our route, defined on our RouteBuilder:
package com.alexandreesl.handson.routes;
import com.alexandreesl.handson.dto.AccessLogDTO;
import org.apache.camel.LoggingLevel;
import org.apache.camel.spring.SpringRouteBuilder;
import org.springframework.context.annotation.Configuration;
/**
* Created by alexandrelourenco on 30/06/17.
*/
@Configuration
public class MyFirstCamelRoute extends SpringRouteBuilder {
@Override
public void configure() throws Exception {
from("file:/Users/alexandrelourenco/Documents/apachecamelhandson?delay=1000&charset=utf-8&delete=true")
.setHeader("CamelAwsS3Key", header("CamelFileName"))
.to("aws-s3:arn:aws:s3:::apache-camel-handson?amazonS3Client=#s3Client")
.convertBodyTo(String.class)
.split().tokenize("\n")
.convertBodyTo(AccessLogDTO.class)
.log(LoggingLevel.INFO, "${body}")
.to("aws-sqs://MyInputQueue?amazonSQSClient=#sqsClient");
}
}
On the route above, we define a file endpoint that will poll for files on a folder, each 1 second and remove the file if the processing is completed successfully. Then we send the file to Amazon using S3 as a backup storage.
Next, we split the file using a splitter, that generates a string for each line of the file. For each line we convert the line to a DTO, log the data and finally we send the data to a SQS.
Now that we have our code done, let’s run it!
Running
First, we start our Camel route. To do this, we simply run the main Spring Boot class, as we would do with any common Java program.
After firing up Spring Boot, we would receive on our console the output that the route was successful started:
. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v1.5.4.RELEASE) 2017-07-01 12:52:02.224 INFO 3042 --- [ main] c.a.handson.ApacheCamelHandsonApp : Starting ApacheCamelHandsonApp on Alexandres-MacBook-Pro.local with PID 3042 (/Users/alexandrelourenco/Applications/git/apache-camel-handson/build/classes/main started by alexandrelourenco in /Users/alexandrelourenco/Applications/git/apache-camel-handson) 2017-07-01 12:52:02.228 INFO 3042 --- [ main] c.a.handson.ApacheCamelHandsonApp : No active profile set, falling back to default profiles: default 2017-07-01 12:52:02.415 INFO 3042 --- [ main] s.c.a.AnnotationConfigApplicationContext : Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@475e586c: startup date [Sat Jul 01 12:52:02 BRT 2017]; root of context hierarchy 2017-07-01 12:52:03.325 INFO 3042 --- [ main] trationDelegate$BeanPostProcessorChecker : Bean 'org.apache.camel.spring.boot.CamelAutoConfiguration' of type [org.apache.camel.spring.boot.CamelAutoConfiguration$$EnhancerBySpringCGLIB$$72a2a9b] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2017-07-01 12:52:09.520 INFO 3042 --- [ main] o.a.c.i.converter.DefaultTypeConverter : Loaded 192 type converters 2017-07-01 12:52:09.612 INFO 3042 --- [ main] roperties$SimpleAuthenticationProperties : Using default password for shell access: b738eab1-6577-4f9b-9a98-2f12eae59828 2017-07-01 12:52:15.463 WARN 3042 --- [ main] tarterDeprecatedWarningAutoConfiguration : spring-boot-starter-remote-shell is deprecated as of Spring Boot 1.5 and will be removed in Spring Boot 2.0 2017-07-01 12:52:15.511 INFO 3042 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup 2017-07-01 12:52:15.519 INFO 3042 --- [ main] o.s.c.support.DefaultLifecycleProcessor : Starting beans in phase 0 2017-07-01 12:52:15.615 INFO 3042 --- [ main] o.a.camel.spring.boot.RoutesCollector : Loading additional Camel XML routes from: classpath:camel/*.xml 2017-07-01 12:52:15.615 INFO 3042 --- [ main] o.a.camel.spring.boot.RoutesCollector : Loading additional Camel XML rests from: classpath:camel-rest/*.xml 2017-07-01 12:52:15.616 INFO 3042 --- [ main] o.a.camel.spring.SpringCamelContext : Apache Camel 2.18.3 (CamelContext: camel-1) is starting 2017-07-01 12:52:15.618 INFO 3042 --- [ main] o.a.c.m.ManagedManagementStrategy : JMX is enabled 2017-07-01 12:52:25.695 INFO 3042 --- [ main] o.a.c.i.DefaultRuntimeEndpointRegistry : Runtime endpoint registry is in extended mode gathering usage statistics of all incoming and outgoing endpoints (cache limit: 1000) 2017-07-01 12:52:25.810 INFO 3042 --- [ main] o.a.camel.spring.SpringCamelContext : StreamCaching is not in use. If using streams then its recommended to enable stream caching. See more details at http://camel.apache.org/stream-caching.html 2017-07-01 12:52:27.853 INFO 3042 --- [ main] o.a.camel.spring.SpringCamelContext : Route: route1 started and consuming from: file:///Users/alexandrelourenco/Documents/apachecamelhandson?charset=utf-8&delay=1000&delete=true 2017-07-01 12:52:27.854 INFO 3042 --- [ main] o.a.camel.spring.SpringCamelContext : Total 1 routes, of which 1 are started. 2017-07-01 12:52:27.854 INFO 3042 --- [ main] o.a.camel.spring.SpringCamelContext : Apache Camel 2.18.3 (CamelContext: camel-1) started in 12.238 seconds 2017-07-01 12:52:27.858 INFO 3042 --- [ main] c.a.handson.ApacheCamelHandsonApp : Started ApacheCamelHandsonApp in 36.001 seconds (JVM running for 36.523)
PS: Don’t forget it to replace the access key and secret with your own!
Now, to test it, we place a file on the polling folder. For testing, we create a file like the following:
10.12.64.3 /api/v1/test1 POST 123 10.12.67.3 /api/v1/test2 PATCH 125 10.15.64.3 /api/v1/test3 GET 166 10.120.64.23 /api/v1/test1 POST 100
We put a file with the content on the folder and after 1 second, the file is gone! Where did it go?
If we check the Amazon S3 bucket interface, we will see that the file was created on the storage:
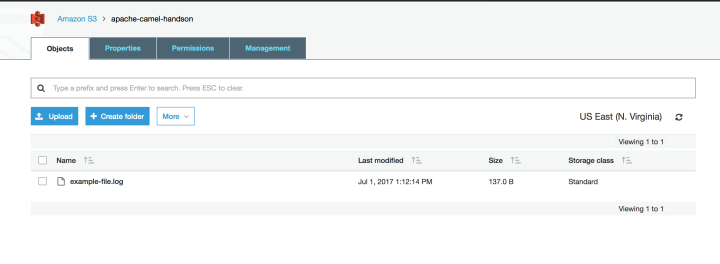
And if we check the Amazon SQS interface, we will see 4 messages on the queue, proving that our integration is a success:

If we check the messages, we will see that Camel correctly parsed the information from the file, as we can see on the example bellow:
[10.12.64.3,/api/v1/test1,POST,123]
Implementing Error Handling
On Camel, we can implement logic designed for handling errors. These are done by defining routes as well, which inputs are the exceptions fired by the routes.
On our lab, let’s implement a error handling. First, we add a option on the file endpoint that makes the file to be moved to a .error folder when a error occurs, and then we send a email to ourselves to alert of the failure. we can do this by changing the route as follows:
package com.alexandreesl.handson.routes;
import com.alexandreesl.handson.dto.AccessLogDTO;
import org.apache.camel.LoggingLevel;
import org.apache.camel.spring.SpringRouteBuilder;
import org.springframework.context.annotation.Configuration;
/**
* Created by alexandrelourenco on 30/06/17.
*/
@Configuration
public class MyFirstCamelRoute extends SpringRouteBuilder {
@Override
public void configure() throws Exception {
onException(Exception.class)
.handled(false)
.log(LoggingLevel.ERROR, "An Error processing the file!")
.to("smtps://smtp.gmail.com:465?password=xxxxxxxxxxxxxxxx&username=alexandreesl@gmail.com&subject=A error has occurred!");
from("file:/Users/alexandrelourenco/Documents/apachecamelhandson?delay=1000&charset=utf-8&delete=true&moveFailed=.error")
.setHeader("CamelAwsS3Key", header("CamelFileName"))
.to("aws-s3:arn:aws:s3:::apache-camel-handson?amazonS3Client=#s3Client")
.convertBodyTo(String.class)
.split().tokenize("\n")
.convertBodyTo(AccessLogDTO.class)
.log(LoggingLevel.INFO, "${body}")
.to("aws-sqs://MyInputQueue?amazonSQSClient=#sqsClient");
}
}
Then, we restart the route and feed up a file like the following, that will cause a parse exception:
10.12.64.3 /api/v1/test1 POST 123 10.12.67.3 /api/v1/test2 PATCH 125 10.15.64.3 /api/v1/test3 GET 166 10.120.64.23 /api/v1/test1 POST 10a
After the processing, we can see the console and watch how the error was handled:
2017-07-01 14:18:48.695 INFO 3230 --- [ main] o.a.camel.spring.SpringCamelContext : Apache Camel 2.18.3 (CamelContext: camel-1) started in 11.899 seconds2017-07-01 14:18:48.695 INFO 3230 --- [ main] o.a.camel.spring.SpringCamelContext : Apache Camel 2.18.3 (CamelContext: camel-1) started in 11.899 seconds2017-07-01 14:18:48.699 INFO 3230 --- [ main] c.a.handson.ApacheCamelHandsonApp : Started ApacheCamelHandsonApp in 35.612 seconds (JVM running for 36.052)2017-07-01 14:18:52.737 WARN 3230 --- [checamelhandson] c.amazonaws.services.s3.AmazonS3Client : No content length specified for stream data. Stream contents will be buffered in memory and could result in out of memory errors.2017-07-01 14:18:53.105 INFO 3230 --- [checamelhandson] route1 : [10.12.64.3,/api/v1/test1,POST,123]2017-07-01 14:18:53.294 INFO 3230 --- [checamelhandson] route1 : [10.12.67.3,/api/v1/test2,PATCH,125]2017-07-01 14:18:53.504 INFO 3230 --- [checamelhandson] route1 : [10.15.64.3,/api/v1/test3,GET,166]2017-07-01 14:18:53.682 ERROR 3230 --- [checamelhandson] route1 : An Error processing the file!2017-07-01 14:19:02.058 ERROR 3230 --- [checamelhandson] o.a.camel.processor.DefaultErrorHandler : Failed delivery for (MessageId: ID-Alexandres-MacBook-Pro-local-52251-1498929510223-0-9 on ExchangeId: ID-Alexandres-MacBook-Pro-local-52251-1498929510223-0-10). Exhausted after delivery attempt: 1 caught: org.apache.camel.InvalidPayloadException: No body available of type: com.alexandreesl.handson.dto.AccessLogDTO but has value: 10.120.64.23 /api/v1/test1 POST 10a of type: java.lang.String on: Message[ID-Alexandres-MacBook-Pro-local-52251-1498929510223-0-9]. Caused by: Error during type conversion from type: java.lang.String to the required type: com.alexandreesl.handson.dto.AccessLogDTO with value 10.120.64.23 /api/v1/test1 POST 10a due java.lang.NumberFormatException: For input string: "10a". Exchange[ID-Alexandres-MacBook-Pro-local-52251-1498929510223-0-10]. Caused by: [org.apache.camel.TypeConversionException - Error during type conversion from type: java.lang.String to the required type: com.alexandreesl.handson.dto.AccessLogDTO with value 10.120.64.23 /api/v1/test1 POST 10a due java.lang.NumberFormatException: For input string: "10a"]. Processed by failure processor: FatalFallbackErrorHandler[Pipeline[[Channel[Log(route1)[An Error processing the file!]], Channel[sendTo(smtps://smtp.gmail.com:465?password=xxxxxx&subject=A+error+has+occurred%21&username=alexandreesl%40gmail.com)]]]] Message History---------------------------------------------------------------------------------------------------------------------------------------RouteId ProcessorId Processor Elapsed (ms)[route1 ] [route1 ] [file:///Users/alexandrelourenco/Documents/apachecamelhandson?charset=utf-8&del] [ 9323][route1 ] [convertBodyTo2 ] [convertBodyTo[com.alexandreesl.handson.dto.AccessLogDTO] ] [ 8370][route1 ] [log1 ] [log ] [ 1][route1 ] [to1 ] [smtps://smtp.gmail.com:xxxxxx@gmail.com&subject=A error ha ] [ 8366] Stacktrace--------------------------------------------------------------------------------------------------------------------------------------- org.apache.camel.InvalidPayloadException: No body available of type: com.alexandreesl.handson.dto.AccessLogDTO but has value: 10.120.64.23 /api/v1/test1 POST 10a of type: java.lang.String on: Message[ID-Alexandres-MacBook-Pro-local-52251-1498929510223-0-9]. Caused by: Error during type conversion from type: java.lang.String to the required type: com.alexandreesl.handson.dto.AccessLogDTO with value 10.120.64.23 /api/v1/test1 POST 10a due java.lang.NumberFormatException: For input string: "10a". Exchange[ID-Alexandres-MacBook-Pro-local-52251-1498929510223-0-10]. Caused by: [org.apache.camel.TypeConversionException - Error during type conversion from type: java.lang.String to the required type: com.alexandreesl.handson.dto.AccessLogDTO with value 10.120.64.23 /api/v1/test1 POST 10a due java.lang.NumberFormatException: For input string: "10a"] at org.apache.camel.impl.MessageSupport.getMandatoryBody(MessageSupport.java:107) ~[camel-core-2.18.3.jar:2.18.3] at org.apache.camel.processor.ConvertBodyProcessor.process(ConvertBodyProcessor.java:91) ~[camel-core-2.18.3.jar:2.18.3] at org.apache.camel.management.InstrumentationProcessor.process(InstrumentationProcessor.java:77) [camel-core-2.18.3.jar:2.18.3] at org.apache.camel.processor.RedeliveryErrorHandler.process(RedeliveryErrorHandler.java:542) [camel-core-2.18.3.jar:2.18.3] at org.apache.camel.processor.CamelInternalProcessor.process(CamelInternalProcessor.java:197) [camel-core-2.18.3.jar:2.18.3]
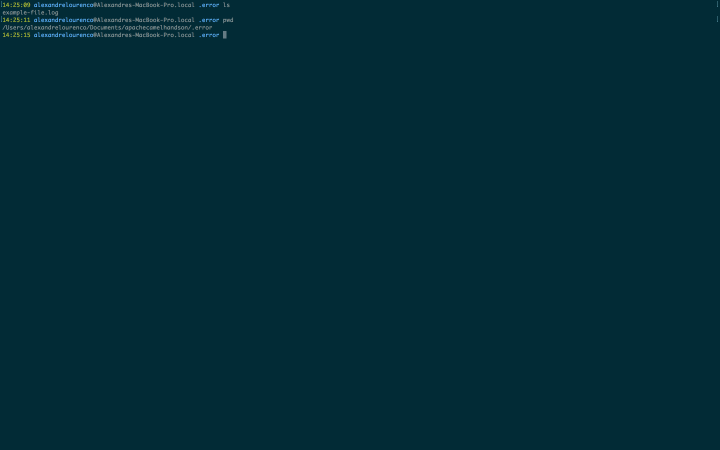
If we look to the folder, we will see that a .error folder was created and the file was moved to the folder:
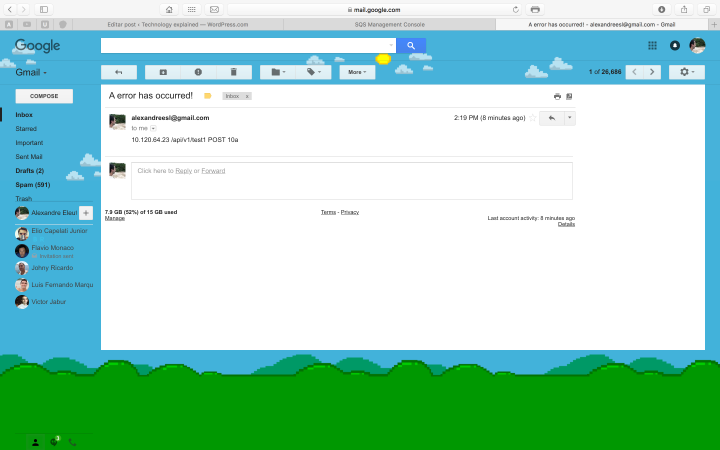
And if we check the mailbox, we will see that we received the failure alert:
Conclusion
And so we conclude our tour through Apache Camel. With a easy-to-use architecture and dozens of components, it is a highly pluggable and robust option on integration developing. Thank you for following me on this post, until next time.