

Welcome, dear reader, to another post of our series about the ELK stack for logging. On the last post, we talked about LogStash, a tool that allow us to integrate data from different sources to different destinations, using transformations along the way, in a stream-like form. On this post, we will talk about ElasticSearch, a indexer based on apache Lucene, which can allow us to organize our data and make textual searches on the data, in a scalable infrastructure. So, let’s begin by understanding how ElasticSearch is organized on the inside
Indexes, documents and shards
On ElasticSearch, we have the concept of indexes. A index is like a repository, where we can store our data in the format of documents. A document on ElasticSearch’s terminology consists of a structure for the data to be stored, analysed and classified, following a mapping definition, composed of a series of fields – a important thing to note, is that a field on ElasticSearch has the same type across the whole index, meaning that we cant have a field “phone” with the type int on a document and the type string on another.
In turn, we have our documents stored on shards, which divide the data on segments based on a rule – by default, the segmentation is made by hashing the data, but it can also be manually manipulated -, making the searches faster.
So, in a nutshell, we can say that the order of organization of ElasticSearch is as follows:
Index >> Document (mappings/type) >> shard
This organization is used by the user on the two basic operations of the cluster: indexing and searching.
One last thing to say about documents is that they can not only be stored as independent , but also be mounted on a tree-like hierarchy, with links between them. This is useful in scenarios that we can make use of hierarchical searches, such as product’s searches based on their categories.
Indexing
Indexing is the action of inputing the data from a external source to the cluster. ElasticSearch is a textual indexer, which means he can only analyse text on plain format, despite that we can use the cluster to store data in base64 format, using a plugin. Later on the post, we will see a example installation of a plugin, which are extensions we can aggregate to expand our cluster usability.
When we index our data, we define which fields are to be analysed, which analyser to use, if the default ones does not suffice and which fields we want to store the data on the cluster, so we can use as the result of our searches. One important thing to note about the indexing operations is that, despite it has CRUD-like operations, the data is not really updated or deleted on the cluster, instead a new version is generated and the old version is marked as deleted.
This is a important thing to take note, because if not properly configured to make purges – which can be made with a configuration that break the shards into segments, and periodically make merges of the segments, phisically deleting the obsolet documents on the process -, the cluster will keep indefinitely expanding in size with the “deleted” older versions of our data, making specially the searches to became really slow.
All the operations can be made with a REST API provided by ElasticSearch, that we will see later on this post.
Searching
The other, and probably most important, action on ElasticSearch, is the searching of the data previously indexed. Like the indexing action, ElasticSearch also provide a REST API for the searches. The API provides a very rich range of possibilities of searching, from basic term searches to more complex searches such as hierarchical searches, searches by synonims, language detections, etc.
All the searching is based on a score system, where formulas are applied to confront the accuracy of the documents founded versus the query supplied. This score system can also be customized.
By default, the searching on the cluster occurs in 2 phases:
- On the first phase, the master node sends the query for all the nodes, and subsequently shards , retrieving just the IDs and scores of the documents. Using a parameter called size which defines the maximum results from a query, the master selects the more meaningful documents, based on the score;
- On the second phase, the master send requests for the nodes to retrieve the documents selected on the previous phase. After receiving the documents, the master finally sends the result for the client;
Alongside this search type, there’s also other modes, like the query_and_fetch. On this mode, the searching is made simultaneous on all shards, not only to retrieve the IDs and scores but also returning the data itself, limited only by the size parameter, which is applied per shard. In turn, on this mode, the maximum of results returned will be the size parameter plus the number of shards.
One interesting feature of ElasticSearch’s configuration options is the ability to make some nodes exclusive to query operations, and others to make the storage part, called data nodes. This way, when we query, our query dont need to run across all the cluster to formulate the results, making the searches faster. On the next section we will see a little more about cluster configurations.
Cluster capabilities
When we talk about a cluster, we talk about scalability, but we also talk about availability. On ElasticSearch, we can configure the replication of shards, where the data is replicated by a given factor, so we dont lose our data if a node is lost. The replication if also maintained by the cluster, so if we lost a replica, the cluster itself will distribute a new replica for another node.
Other interesting feature of the cluster are the ability to discover itself. By the default configuration, when we start a node he will use a discovery mode called Zen, which uses unicast and multicast to search for another instances on all the ports of the OS. If it founds another instance, and the name of the cluster is the same – this is another one of the cluster’s configuration properties. All of this configurations can be made on the file elasticsearch.yml, on the config folder -, it will communicate with the instance and establish a new node for the already running cluster. There is another modes for this feature, including the discover of nodes from other servers.
Logging
The reader could be thinking: “Lol, do I need all of this to run a logging stack?”.
Of course that ElasticSearch is a very robust tool, that can be used on other solutions as well. However, on our case of making a centralized logging analysis solution, the core of ElasticSearch’s capabilities serve us well for this task, after all, we are talking about the textual analysis of log texts, for use on dashboards, reports, or simply for real-time exploration of the data.
Well, that concludes the conceptual part of our post. Now, let’s move on to the practice.
Hands-on
So, without further delay, let’s begin the hands-on. For this, we will use the previous Java program we used on our lab about LogStash. The code can be found on GitHub, on this link. On this program, we used the org.apache.log4j.net.SocketAppender from log4j to send all the logging we make to LogStash. However, on that point we just printed the messages on the console, instead of sending to ElasticSearch. Before we change this, let’s first start our cluster.
To do this, first we need to download the last version from the site and unzip the tar. Let’s open a terminal, and type the following command:
curl https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.4.tar.gz | tar -zx
After running the command, we will find a new folder called “elasticsearch-1.4.4” created on the same folder we run our command. To our example, we will create 2 copies of this folder on a folder we call “elasticsearchcluster”, where each one will represent one node of the cluster. To do this, we run the following commands:
mkdir elasticsearchcluster
sudo cp -avr elasticsearch-1.4.4/ elasticsearchcluster/elasticsearch-1.4.4-node1/
sudo cp -avr elasticsearch-1.4.4/ elasticsearchcluster/elasticsearch-1.4.4-node2/
After we made our cluster structure, we dont need the original folder anymore, so we remove:
rm -R elasticsearch-1.4.4/
Now, let’s finally start our cluster! To do this, we open a terminal, navigate to the bin folder of our first node (elasticsearch-1.4.4-node1) and type:
./elasticsearch
After some seconds, we can see our first node is on:
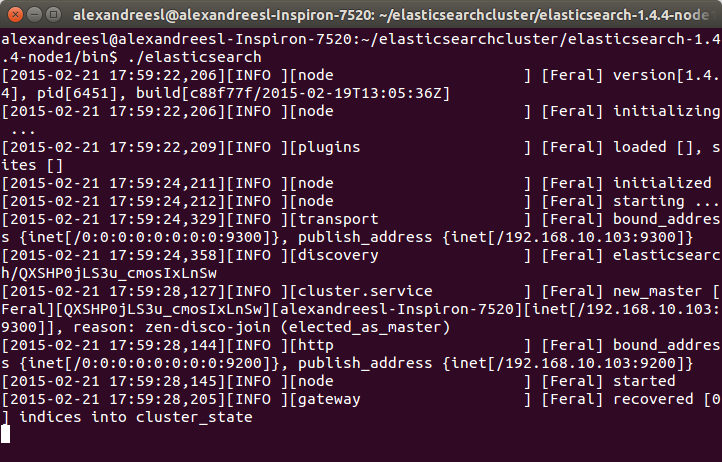 For curiosity sake, we can see the name “Feral” on the node’s name on the log. All the names generated by the tool are based on Marvel Comic’s characters. IT world sure has some sense of humor, heh?
For curiosity sake, we can see the name “Feral” on the node’s name on the log. All the names generated by the tool are based on Marvel Comic’s characters. IT world sure has some sense of humor, heh?
Now, let’s start our second node. On a new terminal window, let’s navigate to the folder of our second node (elasticsearch-1.4.4-node2) and type again the command “./elasticsearch”. After some seconds, we can see that the node is also started:
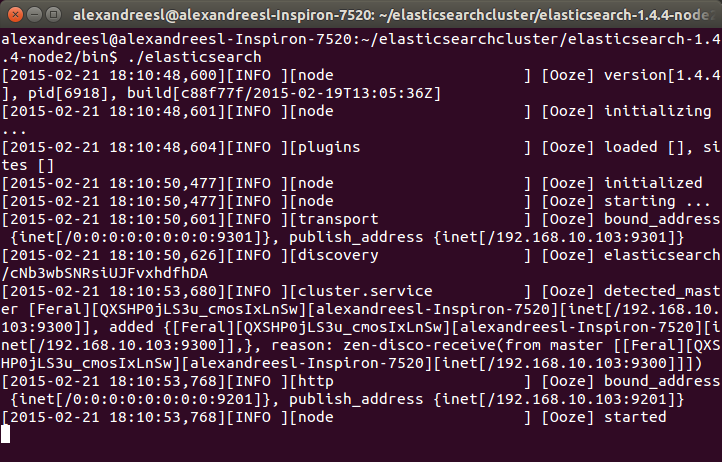
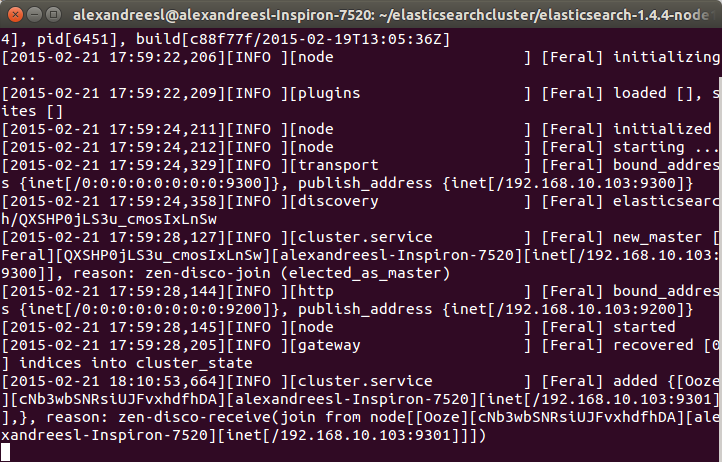
One interesting thing to notice is that our second node “Ooze”, has a mention of comunicating with our other node, “Feral”. That is the zen discover on the action, making the 2 nodes talk to each other and form a cluster. If we look again at the terminal of our first node, we can see another evidence of this bidirectional communication, as “Feral” has added “Ooze” to the cluster, as his role as a master node:
 Now that we have our cluster set up, let’s adjust our logstash script to send the messages to the cluster. To do this, let’s change the output part of the script, to the following:
Now that we have our cluster set up, let’s adjust our logstash script to send the messages to the cluster. To do this, let’s change the output part of the script, to the following:
input {
log4j {
port => 1500
type => “log4j”
tags => [ “technical”, “log”]
}
}output {
stdout { codec => rubydebug }
elasticsearch_http {
host => “localhost”
port => 9200
index => “log4jlogs”
}
}
As we can see, we just included another output – we remained the console output just to check how logstash is receiving the data – including the ip and port where our ElasticSearch cluster will respond. We also defined the name of the index we want our logs to be stored. If this parameter is not defined, logstash will order elasticsearch to create a index with the pattern “logstash-%{+YYYY.MM.dd}”.
To execute this script, we do like we did on the previous post, we put the new script on a file called “configelasticsearch.conf” on the bin folder of logstash, and run with the command:
./logstash -f configelasticsearch.conf
PS1: On the GitHub repository, it is possible to find this config file, alongside a file containing all the commands we will send to ElasticSearch from now on.
PS2: For simplicity sake, we will use the default mappings logstash provide for us when sending messages to the cluster. It is also possible to pass a elasticsearch’s mapping structure, which consists of a JSON model, that logstash will use as a template. We will see the mapping from our log messages later on our lab, but for satisfying the reader curiosity for now, this is what a elasticsearch’s mapping structure look like, for example for a document type “product”:
“mappings” : {
“product”: {
“properties” : {“variation” : { “type” : int }
“color” : { “type” : “string” }
“code” : { “type” : int }
“quantity” : { “type” : int }
}
}
}
After some seconds, we can see that LogStash booted, so our configuration was a success. Now, let’s begin sending our logs!
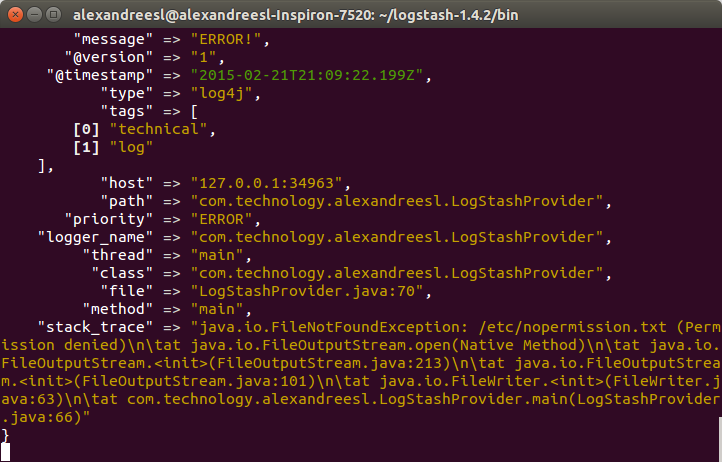
To do this, we run the program from our previous post, running the class com.technology.alexandreesl.LogStashProvider . We can see on the console of logstash, after starting the program, that the messages are going through the stack:
Now that we have our cluster up and running, let’s start to use it. First, let’s see the mappings of the index that ElasticSearch created for us, based on the configuration we made on LogStash. Let’s open a terminal and run the following command:
curl -XGET ‘localhost:9200/log4jlogs/_mapping?pretty’
On the command above, we are using ElasticSearch’s REST API. The reader will notice that, after the ip and port, the URL contains the name of the index we configured. This pattern for calls of the API is applied to most of the actions, as we can see below:
<ip>:<port>/<index>/<doc type>/<action>?<attributes>
So, after this explanation, let’s see the result from our call:
{
“log4jlogs” : {
“mappings” : {
“log4j” : {
“properties” : {
“@timestamp” : {
“type” : “date”,
“format” : “dateOptionalTime”
},
“@version” : {
“type” : “string”
},
“class” : {
“type” : “string”
},
“file” : {
“type” : “string”
},
“host” : {
“type” : “string”
},
“logger_name” : {
“type” : “string”
},
“message” : {
“type” : “string”
},
“method” : {
“type” : “string”
},
“path” : {
“type” : “string”
},
“priority” : {
“type” : “string”
},
“stack_trace” : {
“type” : “string”
},
“tags” : {
“type” : “string”
},
“thread” : {
“type” : “string”
},
“type” : {
“type” : “string”
}
}
}
}
}
}
As we can see, the index “log4jlogs” was created, alongside the document type “log4j”. Also, a series of fields were created, representing information from the log messages, like the thread that generated the log, the class, the log level and the log message itself.
Now, let’s begin to make some searches.
Let’s begin by searching all log messages which the priority was “INFO”. We make this searching by running:
curl -XGET ‘localhost:9200/log4jlogs/log4j/_search?q=priority:info&pretty=true’
A fragment of the result of the query would be something like the following:
{
“took” : 12,
“timed_out” : false,
“_shards” : {
“total” : 5,
“successful” : 5,
“failed” : 0
},
“hits” : {
“total” : 18,
“max_score” : 1.1823215,
“hits” : [ {
“_index” : “log4jlogs”,
“_type” : “log4j”,
“_id” : “AUuxkDTk8qbJts0_16ph”,
“_score” : 1.1823215,
“_source”:{“message”:”STARTING DATA COLLECTION”,”@version”:”1″,”@timestamp”:”2015-02-22T13:53:12.907Z”,”type”:”log4j”,”tags”:[“technical”,”log”],”host”:”127.0.0.1:32942″,”path”:”com.technology.alexandreesl.LogStashProvider”,”priority”:”INFO”,”logger_name”:”com.technology.alexandreesl.LogStashProvider”,”thread”:”main”,”class”:”com.technology.alexandreesl.LogStashProvider”,”file”:”LogStashProvider.java:20″,”method”:”main”}
}.
.
.
As we can see, the result is a JSON structure, with the documents that met our search. The beginning information of the result is not the documents themselves, but instead information about the search itself, such as the number of shards used, the seconds the search took to execute, etc. This kind of information is useful when we need to make a tuning of our searches, like manually defining the shards we which to use on the search, for example.
Let’s see another example. On our previous search, we received all the fields from the document on the result, which is not always the desired result, since we will not always use the whole information. To limit the fields we want to receive, we make our query like the following:
curl -XGET ‘localhost:9200/log4jlogs/log4j/_search?pretty=true’ -d ‘
{
“fields” : [ “priority”, “message”,”class” ],
“query” : {
“query_string” : { “query” : “priority:info” }
}
}’
On the query above, we asked ElasticSearch to limit the return to only return the priority, message and class fields. A fragment of the result can be seen bellow:
.
.
.
{
“_index” : “log4jlogs”,
“_type” : “log4j”,
“_id” : “AUuxkECZ8qbJts0_16pr”,
“_score” : 1.1823215,
“fields” : {
“priority” : [ “INFO” ],
“message” : [ “CLEANING UP!” ],
“class” : [ “com.technology.alexandreesl.LogStashProvider” ]
}
}.
.
.
Now, let’s use the term search. On the term searches, we use ElasticSearch’s textual analysis to find a term inside the text of a field. Let’s run the following command:
curl -XGET ‘localhost:9200/log4jlogs/log4j/_search?pretty=true’ -d ‘
{
“fields” : [ “priority”, “message”,”class” ],
“query” : {
“term” : {
“message” : “up”
}
}
}’
If we see the result, it would be all the log messages that contains the word “up”. A fragment of the result can be seen bellow:
{
“_index” : “log4jlogs”,
“_type” : “log4j”,
“_id” : “AUuxkESc8qbJts0_16pv”,
“_score” : 1.1545612,
“fields” : {
“priority” : [ “INFO” ],
“message” : [ “CLEANING UP!” ],
“class” : [ “com.technology.alexandreesl.LogStashProvider” ]
}
}
Of course, there is a lot more of searching options on ElasticSearch, but the examples provided on this post are enough to make a good starting point for the reader. To make a final example, we will use the “prefix” search. On this type of search, ElasticSearch will search for terms that start with our given text, on a given field. For example, to search for log messages that have words starting with “clea”, part of the word “cleaning”, we run the following:
curl -XGET ‘localhost:9200/log4jlogs/log4j/_search?pretty=true’ -d ‘
{
“fields” : [ “priority”, “message”,”class” ],
“query” : {
“prefix” : {
“message” : “clea”
}
}
}’
If we see the results, we will see that are the same from the previous search, proving that our search worked correctly.
Kopf
The reader possibly could ask “Is there another way to send my queries without using the terminal?” or “Is there any graphical tool that I can use to monitor the status of my cluster?”. As a matter of fact, there is a answer for both of this questions, and the answer is the kopf plugin.
As we said before, plugins are extensions that we can install to improve the capacities of our cluster. In order to install the plugin, first let’s stop both the nodes of the cluster – press ctrl+c on both terminal windows to stop – then, navigate to the nodes root folder and type the following:
bin/plugin -install lmenezes/elasticsearch-kopf
If the plugin was installed correctly, we should see a message like the one bellow on the console:
.
.
.
-> Installing lmenezes/elasticsearch-kopf…
Trying https://github.com/lmenezes/elasticsearch-kopf/archive/master.zip…
Downloading …………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..DONE
Installed lmenezes/elasticsearch-kopf into….
After installing on both nodes, we can start again the nodes, just as we did before. After the booting of the cluster, let’s open a browser and type the following URL:
We will see the following web page of the kopf plugin, showing the status of our cluster, such as the nodes, the indexes, shard information, etc
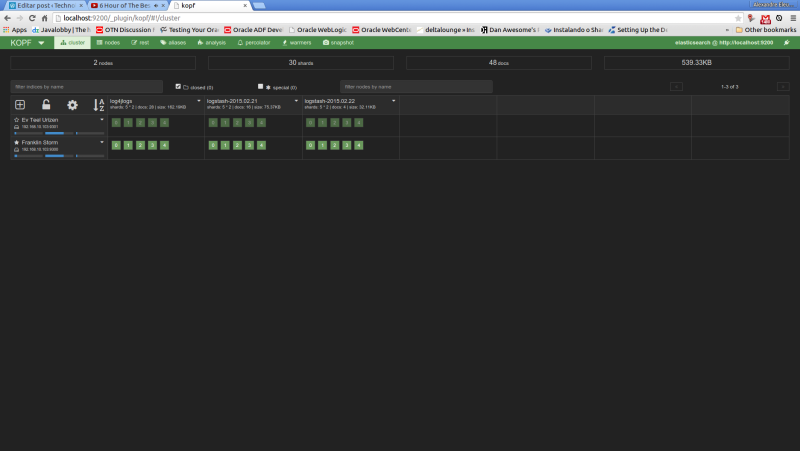
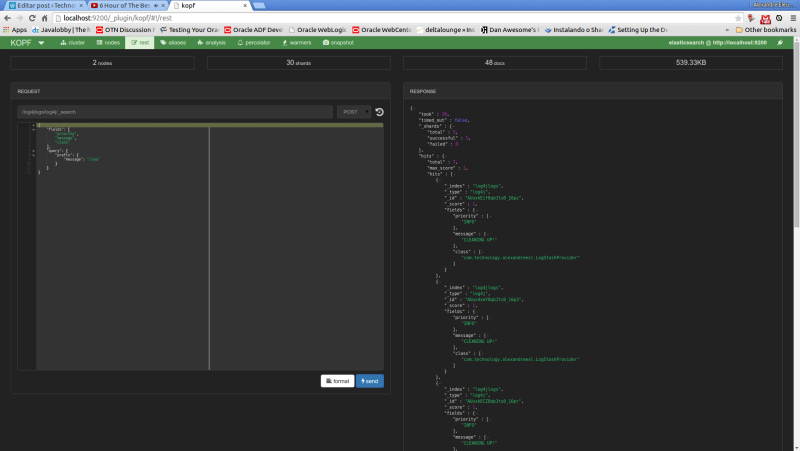
Now, let’s run our last example from the search queries on kopf. First, we select the “rest” option on the top menu. On the next screen, we select “POST” as the http method, include on the URL field the index and document type to narrow the results and on the textarea bellow we include our JSON query filters. The print bellow shows the query made on the interface:
 Conclusion
Conclusion
And so we conclude our post about ElasticSearch. A very powerful tool on the indexing and analysis of textual information, the central stone on our ELK stack for logging is a tool to be used, not only on a logging analysis system, but on other solutions that his features can be useful as well.
So, our stack is almost complete. We can gather our log information, and the information is indexed on our cluster. However, a final piece remains: we need a place where we can have a more friendly interface, that allow us not only to search the information, but also to make rich presentations of the data, such as dashboards. That’s when it enters our last part of our ELK series and the last tool we will see, Kibana. Thank you for following me on another post, until next time.
