
Hello, dear readers! welcome to my blog. On this post, we will learn about AWS Lambda, a serverless architectural solution that enables us to quickly deploy serverless back-end infrastructures. But why using this service, instead of good old EC2s?Let’s find it out!
Motivation behind AWS Lambda
Alongside the benefits of developing a back-end using the serverless paradigm – which can be learned on more detail on this other post of mine – another good point on using AWS is pricing.
When deploying your application with a EC2, be a on-demand, spot or reserved one, we are charged by hour. This is true even if our application is not called at all during that hour, resulting on wasted resources and money.
With AWS lambda, Amazon charge us by processing time, as such, it only charges us the time spent on lambdas execution. This results on a much cleaner architecture, where less resources and money are spent. This post details the case on more detail.
AWS Lambda development is based on functions. When developing a lambda, we develop a function that can run as a REST endpoint – served by Amazon API Gateway – or a event processing function, running on events such as a file been uploaded to a S3 bucket.
Limitations
However, not all is simple on this service. When developing with AWS Lambda, two things must be kept in mind: cold starts and resource restrictions.
Cold starts consist of the first time a lambda is called, or after some time is passed and the server – behind the scenes, obviously there are servers that runs the functions, but this is hidden from the user – used to run the lambda is already down due to inactivity. Amazon has algorithms that make the server be up and serving as long as there is a consistent frequency of client calls, but off course, from time to time, there will be idle times.
When a cold start is made, this causes the requests to have a more slow response, since it will wait for a server to be up and running to run the function. This can be worsen if clients have low timeout configurations, resulting on requests failing. This should be taking on account when developing lambdas that act as APIs.
Another important aspect to take note are resource restrictions. Been designed to be used for small functions (“microservices”), lambdas have several limitations, such as amount of memory, disk and cpu. This limits can be increased, but only by a small amount. This link on AWS docs details more about the limits.
One important limit is the running time of the lambda itself. A AWS Lambda can run at most 5 minutes. This is a important limit to understand the nature of what lambdas must be in nature: simple functions, that must not run by long periods of time.
If any of this limits are reached, the lambda will fail his execution.
Lab
For this lab, we will use a framework called Serverless. Serverless is a framework that automates for us some tasks that are a little boring to do if developing with AWS Lambda by hand, such as creating a zip file with all our sources to be uploaded to S3 and creating/configuring all AWS resources. Serverless uses CloudFormation under the hood, managing resource creation and updates for us. For programming language, we will use Python 3.6.
To install Serverless, please follow this guide.
With Serverless installed, let’s begin our lab! First, let’s create a project, by running:
serverless create --template aws-python3 --path MyAmazingAWSLambdaService
This command will create a new Serverless project, using a initial template for our first Python lambda. Let’s open the project – I will be using PyCharm, but any IDE or editor of choice will suffice – and see what the framework created for us.
Project structure
Serverless created a simple project structure, consisting of a serverless YAML file and a Python script. It is on the YAML that we declare our functions, the cloud provider, IAM permissions, resources to be created etc.
The file created by the command is as follows:
# Welcome to Serverless!
#
# This file is the main config file for your service.
# It's very minimal at this point and uses default values.
# You can always add more config options for more control.
# We've included some commented out config examples here.
# Just uncomment any of them to get that config option.
#
# For full config options, check the docs:
# docs.serverless.com
#
# Happy Coding!
service: MyAmazingAWSLambdaService
# You can pin your service to only deploy with a specific Serverless version
# Check out our docs for more details
# frameworkVersion: "=X.X.X"
provider:
name: aws
runtime: python3.6
# you can overwrite defaults here
# stage: dev
# region: us-east-1
# you can add statements to the Lambda function's IAM Role here
# iamRoleStatements:
# - Effect: "Allow"
# Action:
# - "s3:ListBucket"
# Resource: { "Fn::Join" : ["", ["arn:aws:s3:::", { "Ref" : "ServerlessDeploymentBucket" } ] ] }
# - Effect: "Allow"
# Action:
# - "s3:PutObject"
# Resource:
# Fn::Join:
# - ""
# - - "arn:aws:s3:::"
# - "Ref" : "ServerlessDeploymentBucket"
# - "/*"
# you can define service wide environment variables here
# environment:
# variable1: value1
# you can add packaging information here
#package:
# include:
# - include-me.py
# - include-me-dir/**
# exclude:
# - exclude-me.py
# - exclude-me-dir/**
functions:
hello:
handler: handler.hello
# The following are a few example events you can configure
# NOTE: Please make sure to change your handler code to work with those events
# Check the event documentation for details
# events:
# - http:
# path: users/create
# method: get
# - s3: ${env:BUCKET}
# - schedule: rate(10 minutes)
# - sns: greeter-topic
# - stream: arn:aws:dynamodb:region:XXXXXX:table/foo/stream/1970-01-01T00:00:00.000
# - alexaSkill
# - alexaSmartHome: amzn1.ask.skill.xx-xx-xx-xx
# - iot:
# sql: "SELECT * FROM 'some_topic'"
# - cloudwatchEvent:
# event:
# source:
# - "aws.ec2"
# detail-type:
# - "EC2 Instance State-change Notification"
# detail:
# state:
# - pending
# - cloudwatchLog: '/aws/lambda/hello'
# - cognitoUserPool:
# pool: MyUserPool
# trigger: PreSignUp
# Define function environment variables here
# environment:
# variable2: value2
# you can add CloudFormation resource templates here
#resources:
# Resources:
# NewResource:
# Type: AWS::S3::Bucket
# Properties:
# BucketName: my-new-bucket
# Outputs:
# NewOutput:
# Description: "Description for the output"
# Value: "Some output value"
For now, let’s just remove all comments in order to have a cleaner file. The other file is a Python script, which have our first function. Let’s see it:
import json
def hello(event, context):
body = {
"message": "Go Serverless v1.0! Your function executed successfully!",
"input": event
}
response = {
"statusCode": 200,
"body": json.dumps(body)
}
return response
# Use this code if you don't use the http event with the LAMBDA-PROXY
# integration
"""
return {
"message": "Go Serverless v1.0! Your function executed successfully!",
"event": event
}
"""
As we can see, is a pretty simple script. All we have to do is create a function that receives 2 parameters, context and event. Event is used to pass the input data on which the lambda will work. Context is used by AWS to pass information about the environment on which the lambda is running. For example, if we wanted to know how much time is left before our running time limit is reached, we could do the following call:
print("Time remaining (MS):", context.get_remaining_time_in_millis())
The dictionary returned by the function is the standard response for a lambda that acts as a API, proxied by AWS API Gateway.
For now, let’s leave the script as it is, as we will add more functions to the project. Let’s begin by adding the Dynamodb table we will use on our lab, alongside other configurations.
Creating Dynamodb table
In order to create the table, we modify our YAML as follows:
service: MyAmazingAWSLambdaService
provider:
name: aws
runtime: python3.6
stage: ${opt:stage, 'dev'}
region: ${opt:region, 'us-east-1'}
profile: personal
functions:
hello:
handler: handler.hello
resources:
Resources:
product:
Type: AWS::DynamoDB::Table
Properties:
TableName: product
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
We added a resources section, where we defined a dynamodb table called product and defined a atribute called id to be key in table’s items. We also defined the stage and region to be collected as command-line options – stages are used as application environments, such as QA and Production. Finally, we defined that we want the deploys to use a IAM profile called personal. This is useful when having several accounts on the same machine.
Let’s deploy the stack by entering:
serverless deploy --stage prod
After some time, we will see that our stack was successfully deployed, as we can see on the console:
Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Creating Stack... Serverless: Checking Stack create progress... ..... Serverless: Stack create finished... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service .zip file to S3 (3.38 KB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... .................. Serverless: Stack update finished... Service Information service: MyAmazingAWSLambdaService stage: prod region: us-east-1 stack: MyAmazingAWSLambdaService-prod api keys: None endpoints: None functions: hello: MyAmazingAWSLambdaService-prod-hello
During the deployment, Serverless generated a zip file with all our resources, uploaded to a bucket, created a CloudFormation stack and deployed our lambda with it, alongside the necessary permissions to run. It also created our dynamodb table, as required.
Now that we have our stack and table, let’s begin by creating a group of lambdas to implement CRUD operations on our table.
Creating CRUD lambdas
Now, let’s create our lambdas. First, let’s create a Python class to encapsulate the operations on our dynamodb table:
# -*- coding: UTF-8 -*-
import boto3
dynamodb = boto3.resource('dynamodb')
class DynamoDbHelper:
def __init__(self, **kwargs):
self.table = dynamodb.Table(kwargs.get('table', """missing"""))
def save(self, entity):
"""
save entity from DYNAMODB_self.table
"""
saved = self.table.put_item(Item=entity)
print('Saving result: ({})'.format(saved))
def get(self, entity_id):
"""
get entity from DYNAMODB_self.table
"""
entity = self.table.get_item(Key={'id': entity_id})
if 'Item' in entity:
return entity['Item']
else:
return None
def delete(self, entity_id):
"""
delete entity from DYNAMODB_self.table
"""
deleted = self.table.delete_item(Key={'id': entity_id})
print('Deleting result: ({})'.format(deleted))
Then, we create another script to make a converter. This will be used to read the input data from lambda calls to dynamodb’s data:
# -*- coding: UTF-8 -*-
import json
class ProductConverter:
def convert(self, event):
"""
convert entity from input to dictionary to be saved on dynamodb
"""
if isinstance(event['body'], dict):
data = event['body']
else:
data = json.loads(event['body'])
return {
'id': data['id'],
'name': data.get('name', ''),
'description': data.get('description', ''),
'price': data.get('price', '')
}
Next, we change the script created by Serverless, creating the lambda handlers:
# -*- coding: UTF-8 -*-
import json
from helpers.DynamoDbHelper import DynamoDbHelper
from helpers.ProductConverter import ProductConverter
def get_path_parameters(event, name):
return event['pathParameters'][name]
dynamodb_helper = DynamoDbHelper(table='product')
product_converter = ProductConverter()
def save(event, context):
product = product_converter.convert(event)
if 'id' not in event['body']:
return {
"statusCode": 422,
"body": json.dumps({'message': 'Product ID is required!'})
}
try:
dynamodb_helper.save(product)
response = {
"statusCode": 200,
"body": json.dumps({'message': 'saved successfully'})
}
except Exception as e:
return {
"statusCode": 500,
"body": json.dumps({'message': str(e)})
}
return response
def get(event, context):
product = dynamodb_helper.get(get_path_parameters(event, 'product_id'))
if product is not None:
response = {
"statusCode": 200,
"body": json.dumps(product)
}
else:
response = {
"statusCode": 404,
"body": json.dumps({'message': 'not found'})
}
return response
def delete(event, context):
try:
dynamodb_helper.delete(get_path_parameters(event, 'product_id'))
response = {
"statusCode": 200,
"body": json.dumps({'message': 'deleted successfully'})
}
except Exception as e:
return {
"statusCode": 500,
"body": json.dumps({'message': str(e)})
}
return response
Finally, we change serverless.yml, defining our lambdas to be deployed on AWS:
service: MyAmazingAWSLambdaService
provider:
name: aws
runtime: python3.6
stage: ${opt:stage, 'dev'}
region: ${opt:region, 'us-east-1'}
profile: personal
iamRoleStatements: # permissions for all of your functions can be set here
- Effect: Allow
Action:
- dynamodb:*
Resource: "arn:aws:dynamodb:us-east-1:<your_account_id>:table/product"
functions:
save_product:
handler: handler.save
events:
- http:
path: product/save
method: post
update_product:
handler: handler.save
events:
- http:
path: product/update
method: patch
get_product:
handler: handler.get
events:
- http:
path: product/{product_id}
method: get
delete_product:
handler: handler.delete
events:
- http:
path: product/{product_id}
method: delete
resources:
Resources:
product:
Type: AWS::DynamoDB::Table
Properties:
TableName: product
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
After running the deployment again, we can see the functions were deployed, as seen on terminal:
Serverless: Packaging service...
Serverless: Excluding development dependencies...
Serverless: Uploading CloudFormation file to S3...
Serverless: Uploading artifacts...
Serverless: Uploading service .zip file to S3 (4.92 KB)...
Serverless: Validating template...
Serverless: Updating Stack...
Serverless: Checking Stack update progress...
........................................................................................
Serverless: Stack update finished...
Service Information
service: MyAmazingAWSLambdaService
stage: prod
region: us-east-1
stack: MyAmazingAWSLambdaService-prod
api keys:
None
endpoints:
POST - https://xxxxxxxxxxxx.execute-api.us-east-1.amazonaws.com/prod/product/save
PATCH - https://xxxxxxxxxxxx.execute-api.us-east-1.amazonaws.com/prod/product/update
GET - https://xxxxxxxxxxxx.execute-api.us-east-1.amazonaws.com/prod/product/{product_id}
DELETE - https://xxxxxxxxxxxx.execute-api.us-east-1.amazonaws.com/prod/product/{product_id}
functions:
save_product: MyAmazingAWSLambdaService-prod-save_product
update_product: MyAmazingAWSLambdaService-prod-update_product
get_product: MyAmazingAWSLambdaService-prod-get_product
delete_product: MyAmazingAWSLambdaService-prod-delete_product
PS: the rest api id was intentionally masked by me for security reasons.
On terminal, we can also see the URLs to call our lambdas. On AWS lambda, the URLs follows this pattern:
https://{restapi_id}.execute-api.{region}.amazonaws.com/{stage_name}/
Later on our lab we will learn how to test our lambdas. For now, let’s learn how to create our last lambda, the one that will read from S3 events.
Creating S3 lambda to bulk create to Dynamodb
Now, let’s implement a lambda that will bulk process product inserts. This lambda will use a csv file as parameter, receiving chunks of data. The lambda will process the data as a stream, using the streaming interface from boto3 behind the hood, saving products as it reads them. To facilitate, we will use Pandas Python library to read the csv . The lambda code is as follows:
# -*- coding: UTF-8 -*-
import boto3
import pandas as pd
import io
from helpers.DynamoDbHelper import DynamoDbHelper
s3 = boto3.client('s3')
dynamodb_helper = DynamoDbHelper(table='product')
def bulk_insert(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
print('Bucket: ' + bucket)
print('Key: ' + key)
obj = s3.get_object(Bucket=bucket, Key=key)
products = pd.read_csv(io.BytesIO(obj['Body'].read()))
products_records = products.fillna('').to_dict('records')
for product in products_records:
record = {
'id': str(product['id']),
'name': product.get('name', ''),
'description': product.get('description', ''),
'price': str(product.get('price', '0'))
}
dynamodb_helper.save(record)
You may notice that we iterate over a list to read bucket files. That’s because AWS can bulk S3 changes to call our lambda fewer times, so we need to read all references that are sent to us.
Before moving on to serverless.yml changes, we need to install a plugin called serverless-python-requirements. This plugin is responsible for adding our pip requirements to lambda packaging.
First, let’s create a file called package.json, with the following. This file must be created by the npm init command:
{
"name": "myamazingawslambdaservice",
"version": "1.0.0",
"description": "",
"main": "index.js",
"author": "",
"license": "ISC"
}
Next, let’s install the plugin, using npm:
npm install --save serverless-python-requirements
And finally, add the plugin to serverless.yml. Here it is all the changes needed for the new lambda:
service: MyAmazingAWSLambdaService
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: non-linux
provider:
name: aws
runtime: python3.6
stage: ${opt:stage, 'dev'}
region: ${opt:region, 'us-east-1'}
profile: personal
iamRoleStatements: # permissions for all of your functions can be set here
- Effect: Allow
Action:
- dynamodb:*
Resource: "arn:aws:dynamodb:us-east-1:<your_account_id>:table/product"
- Effect: Allow
Action:
- s3:GetObject
Resource: "arn:aws:s3:::myamazingbuckets3/*"
functions:
bulk_insert:
handler: bulk_handler.bulk_insert
events:
- s3:
bucket: myamazingbuckets3
event: s3:ObjectCreated:*
save_product:
handler: handler.save
events:
- http:
path: product/save
method: post
update_product:
handler: handler.save
events:
- http:
path: product/update
method: patch
get_product:
handler: handler.get
events:
- http:
path: product/{product_id}
method: get
delete_product:
handler: handler.delete
events:
- http:
path: product/{product_id}
method: delete
resources:
Resources:
product:
Type: AWS::DynamoDB::Table
Properties:
TableName: product
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
PS: because of the plugin, is now needed to have Docker running on deployment. This is because the plugin uses Docker to compile Python packages that requires OS binaries to be installed. The first time you run it, you may notice the process ‘hangs’ at docker step. This is because is downloading the docker image, which is quite sizeable (about 600Mb).
All we had to do is add IAM permissions to the bucket and define the lambda, adding a event to fire at object creations on the bucket. It is not needed to add the bucket to the resource creation section, as Serverless will already create the bucket as we defined that will be used by a lambda on the project.
Now, let’s test the bulk insert. After redeploying, let’s create a csv like following:
id,name,description,price 1,product 1,description 1,125.23 2,product 2,description 2,133.43 3,product 3,description 3,142.24
Let’s save the file and upload to our bucket. After some instants, we will see that our DynamoDB table will be populated with the data, as we can see bellow:
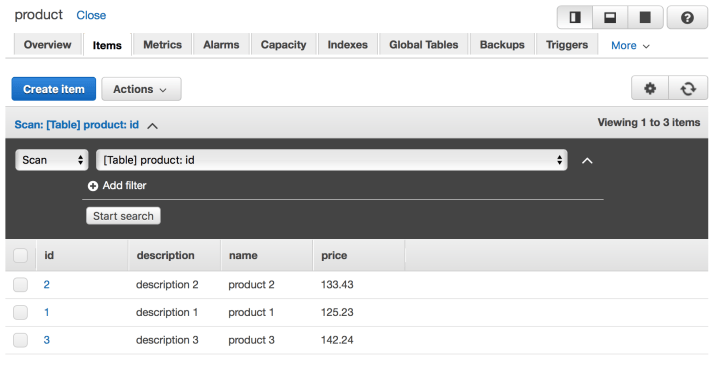
DynamoDB table populated with csv bulk data
Now that we have all our lambdas developed, let’s learn how to test locally and invoke our lambdas from different locations.
Testing local
Let’s test locally our insert product lambda. First, we need to create a json file to hold our test data. Let’s call it example_json.json :
{
"body": {
"id": "123",
"name": "product 1",
"description": "description 1",
"price": "123.24"
}
}
Next, let’s run locally by using Serverless, with the following command:
serverless invoke local --function save_product --path example_json.json
PS: Before running, don’t forget to set the AWS_PROFILE env variable to your profile.
After some instants, we will see the terminal outputting as follows:
Serverless: Invoke invoke:local
Saving result: ({'ResponseMetadata': {'RequestId': '0CDUDLGJEU7UBLLSCQ82SF0B53VV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Mon, 14 May 2018 15:13:22 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '2', 'connection': 'keep-alive', 'x-amzn-requestid': '0CDUDLGJEU7UBLLSCQ82SF0B53VV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '2745614147'}, 'RetryAttempts': 0}})
{
"statusCode": 200,
"body": "{\"message\": \"saved successfully\"}"
}
Behind the hood, Serverless is creating a emulated environment as close as it gets to AWS lambda environment, using the permissions described on the YAML to emulate the permissions set for the function.
It is important to notice that the framework doesn’t guarantee 100% accuracy with a real lambda environment, so more testing in a separate stage – QA, for example – is still necessary before going to production.
Testing on AWS API gateway
To test with AWS API gateway interface, is pretty simple: simply navigate to API Gateway inside Amazon console, then select prod-MyAmazingAWSLambdaService API, navigate to the POST endpoint for example, and select the TEST link.
Provide a JSON like the one we used on our local test – but without the body atribute, moving the attributes to the root – and run it. The API will run successfully, as we can see on the picture bellow:
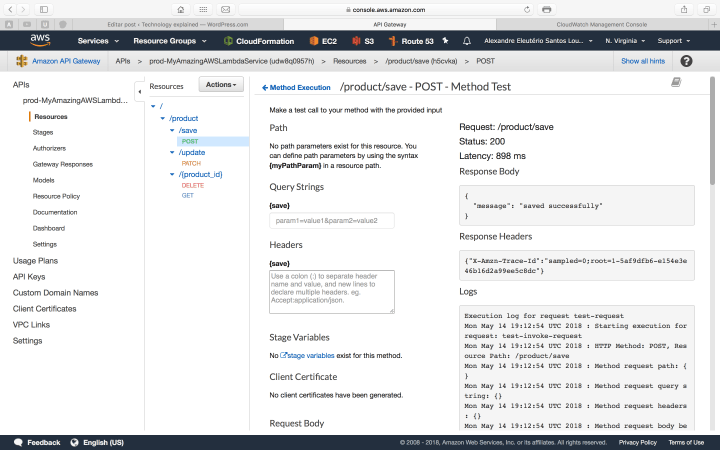
AWS Lambda running on API Gateway
Testing as a consumer
Finally, let’s test like a consumer would call our API. For that, we will use curl. We open a terminal and run:
curl -d '{ "id": "123", "name": "product 1", "description": "description 1", "price": "123.24" }' -H "Content-Type: application/json" -X POST https://<your_rest_api_id>.execute-api.us-east-1.amazonaws.com/prod/product/save
This will produce the following output:
{"message": "saved successfully"}%
Proving our API is successfully deployed for consuming!
Adding security (API keys)
In our previous example, our API is exposed without security to the open world. Of course, on a real scenario, this is not good. It is possible to integrate lambda with several security solutions such as AWS Cognito, to improve security. In our lab, we will use basic API token authentication provided by AWS API gateway.
Let’s change our YAML as follows:
...omitted....
functions:
bulk_insert:
handler: bulk_handler.bulk_insert
events:
- s3:
bucket: myamazingbuckets3
event: s3:ObjectCreated:*
save_product:
handler: handler.save
events:
- http:
path: product/save
method: post
private: true
update_product:
handler: handler.save
events:
- http:
path: product/update
method: patch
private: true
get_product:
handler: handler.get
events:
- http:
path: product/{product_id}
method: get
private: true
delete_product:
handler: handler.delete
events:
- http:
path: product/{product_id}
method: delete
private: true
...omitted....
Now, after redeploying, if we try to make our previous curl, we will receive the following error:
{"message":"Forbidden"}%
So, how do we call it now? First, we need to enter API Gateway and generate a API key, as bellow:
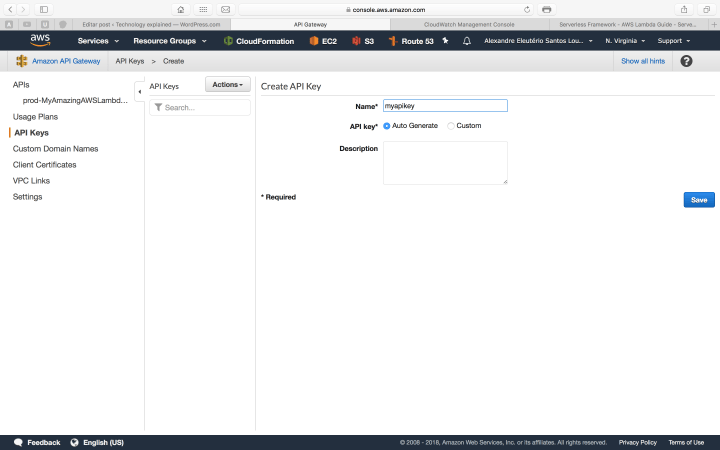
API gateway keys
Secondly, we need to create a usage plan, to associate the key with our API. We do this by following the steps bellow inside API gateway interface:
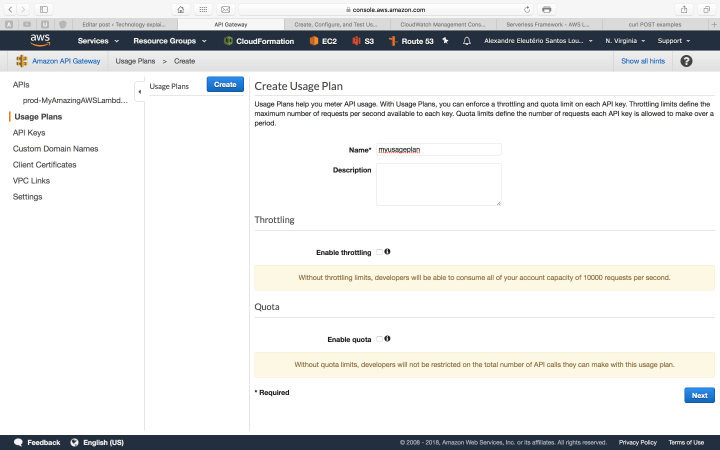
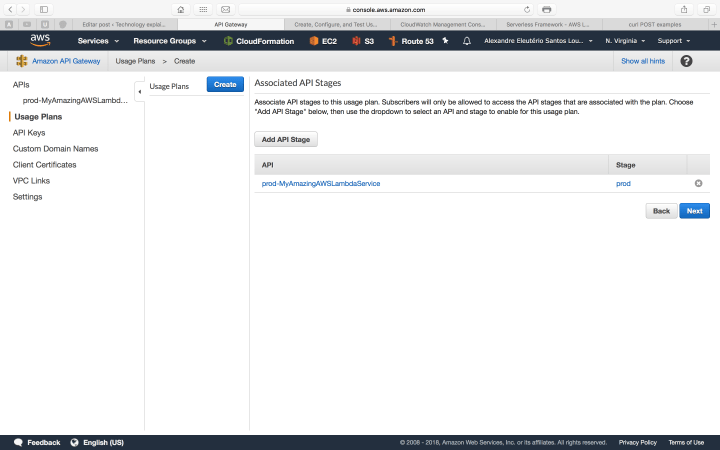
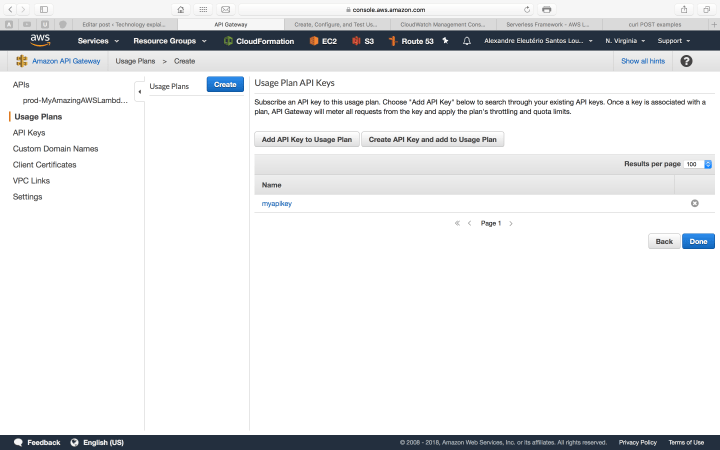
With our key in hand, let’s try again our curl call, adding the header to pass our key:
curl -d '{ "id": "123", "name": "product 1", "description": "description 1", "price": "123.24" }' -H "Content-Type: application/json" -H "x-api-key: <your_API_key>" -X POST https://udw8q0957h.execute-api.us-east-1.amazonaws.com/prod/product/save
After the call, we will receive again the saved successfully response, proving our configuration was successful.
Lambda Logs (CloudWatch)
One last thing we will talk about is logging on AWS Lambda. The reader may noticed the use of Python’s print function in our code. On AWS Lambda, the prints done by Python are collected and organised inside another AWS service, called CloudWatch. We can access CloudWatch on the Amazon Console, as follows:
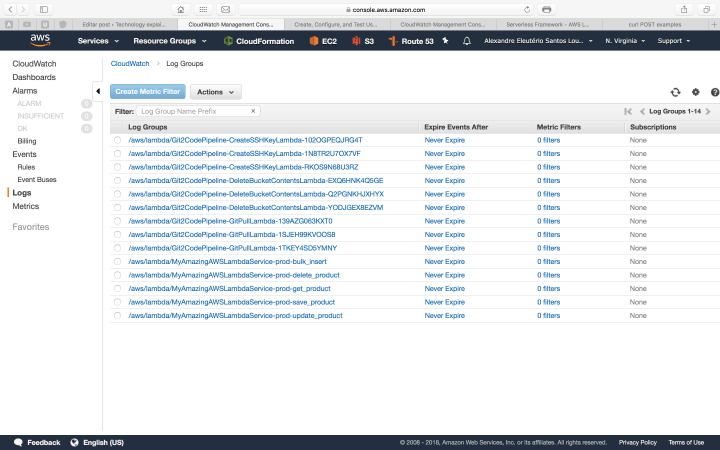
CloudWatch logs list
On the list above, we have each function separated as a link. If we drill down inside one of the links, we will see another link list of each execution made by that function. The print bellow is a example of one of our lambda’s executions:
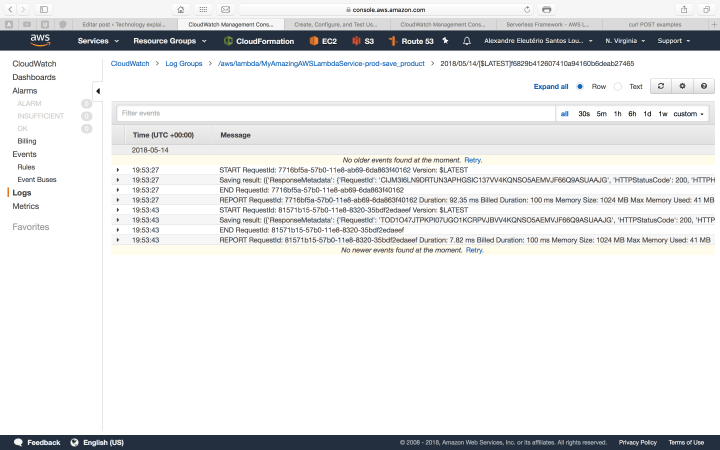
Lambda execution log
Conclusion
And so we concluded our tour through AWS Lambda. With a simple and intuitive approach, it is a good option to deploy applications back-ends following the microservices paradigm. Thank you for following me on this post, until next time.
